
本文在回顾分布式
深度
强化学习
DDRL 基本框架的基础上,重点介绍了 IMPALA 框架系列方法。
围棋
手的 agent 机器人。随着 AlphaGo 的突破,
深度
强化学习
(Deep Reinforcement Learning,DRL)成为一种公认的解决连续决策问题的有效技术。人们开发了大量算法来解决介于 DRL 与现实世界应用之间的挑战性问题,如探索与开发困境、数据低效、多 agent 合作与竞争等。在所有这些挑战中,由于 DRL 的试错学习机制需要大量交互数据,数据低效(data inefficiency)是最受诟病的问题。为了应对这一问题,受到分布式
机器学习
技术的启发,分布式
深度
强化学习
(distributed deep reinforcement learning,DDRL) 已提出并成功应用于
计算机视觉
和
自然语言处理
领域。有观点认为,分布式
强化学习
是
深度
强化学习
走向大规模应用、解决复杂决策空间和长期
规划
问题的必经之路。
策略网络
参数
驱动环境交互以生成数据,以及通过消耗数据更新
策略网络
参数
。这种结构化模式使得对 DRL 进行分布式化处理变得可行,并陆续研发出了大量 Distributed DRL (DDRL) 算法。此外,为了使 DDRL 算法能够利用多台机器,还需要解决几个工程问题,如机器通信和分布式存储,以及在保证算法优化
收敛
性的同时,尽可能地提升其中各个环节的效率。分布式
强化学习
是一个综合的研究子领域,需要
深度
强化学习
算法以及分布式系统设计的互相
感知
和协同。考虑到 DDRL 的巨大进步,我们有必要梳理 DDRL 技术的发展历程、挑战和机遇,从而为今后的研究提供线索。
强化学习
快速发展,关于分布式
强化学习
的架构、算法、关键技术等的研究论文众多。我们将分为两个 part 分别介绍 DDRL 的前世(经典方法)和今生(最新进展)。本文为 part 1,在回顾 DDRL 基本框架的基础上,重点介绍 IMPALA 框架系列方法,主要思路是:使用异步架构,在提升样本吞吐量的同时,引入一些 off-policy 修正。
1、基本框架介绍
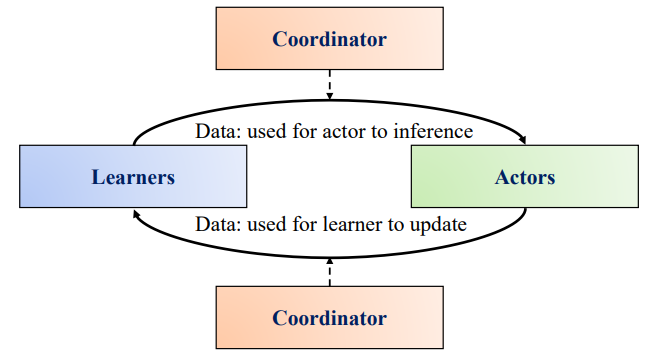
图 1. DDRL 的基本框架
框架
并不针对特定的
强化学习
算法,它们更像是各种
强化学习
方法的
分布式框架
。一般来说,基本的 DDRL 主要有三个部分,它们构成了 single player single agent DDRL 方法:
-
行动者(Actors):通过与环境互动产生数据(轨迹或梯度)。
-
学习者(Learners):消耗数据(轨迹或梯度),执行
神经网络
参数
更新。
-
协调者(Coordinator):协调数据(
参数
或轨迹),控制 learner 和 actor 之间的通信。
参数
更新和拉取(由 actor 进行)时,DDRL 算法就是同步的。当
参数
更新和拉取(actor)没有严格协调时,DDRL 算法就是异步的。因此,可以根据协调者类型对 DDRL 算法进行基本分类。
-
同步:全局策略
参数
的更新是同步的,策略
参数
的调用(由 actor 调用)也是同步的,即不同的 actor 共享相同的最新全局策略。
-
异步:全局策略
参数
的更新是异步的,或者说策略更新(由 learner 进行)和拉动(由 actor 进行)是异步的,即 actor 和 learner 通常拥有不同的策略
参数
。
人工智能
的 DDRL 算法,如
AlphaStar
、OpenAI Five 和 JueWU,要构建多 agent DDRL,有两个关键要素必不可少,即 agent 合作和进化,如图 2 所示。

图 2. single player(agent) single agent DDRL 到 multiple players(agents) multipleagents DDRL
强化学习
算法,agent 合作模块用于训练多个 agents。一般来说,多 agent
强化学习
可以根据 agent 关系建模的方式分为独立训练和联合训练两类。
-
独立训练:将其他学习 agent 视为环境的一部分,对每个 agent 进行独立训练。
-
联合训练:将所有 agent 作为一个整体进行训练,同时考虑 agent 交流、奖励分配、集中训练与分布式执行等因素。
AlphaStar
和 OpenAI Five。根据目前主流的进化技术,进化可分为两种类型:
-
Self-play based:不同 agent 共享相同的
策略网络
,agent 通过与自己过去的版本对抗来更新当前一代的策略。
-
Population-play based:不同的 agent 拥有不同的
策略网络
,或称为 population,agent 通过与其他 agent 或 / 和其过去的版本对抗来更新其当前一代的策略。

图 3. 分布式
深度
强化学习
分类法 [1]
2、经典方法介绍
强化学习
方法。这些方法多为前几年提出的,其性能与最新方法仍有差距,我们在 part1 中回顾这些经典方法,以了解分布式
强化学习
发展初期,重点在哪些方面对传统的
强化学习
以及分布式架构进行了改进。
2.1 Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architecture [2]

DeepMind
推出的一种异步分布式
深度
强化学习
架构,目的是让一个 Agent(single agent)学会多种技能(https://github.com/deepmind/lab/tree/master/game_scripts/levels/contributed/dmlab30)。相关内容发表在 ICML 2018 中。ICML 2018 是第 35 届国际
机器学习
会议,在斯德哥尔摩举办。ICML 2018 共有 2473 篇有效投稿,其中 618 篇被接收,接收率为 25.1%。
异步架构
。与 IMPALA 架构同时提出的还有任务集合 DMLab-30。

图 4. 左图:singer learner。每个 actor 生成轨迹并通过队列发送给 learner。在开始下一个轨迹之前,actor 会从 learner 那里获取最新的策略
参数
;右图:多个同步 learner。策略
参数
分布在多个同步工作的 learner 中
行为策略(Behavior Policy)就是智能体用来和环境交互产生样本的策略;目标策略(Target Policy)就是根据行为策略产生的样本来不断学习和优化的策略,即训练完成最终用来使用的策略。
参数
是分离的。该架构由一组重复生成经验轨迹(trajectory)的 actor 和一个或多个 learner 组成,learner 利用 actor 发送的经验来学习 off policy π。在每条轨迹开始时,actor 会将自己的本地策略 µ 更新为最新的 learner 策略 π,并在其环境中运行 n 步。n 步之后,actor 将状态、行动和奖励的轨迹 x_1、a_1、r_1、…… 、 x_n、a_n、r_n 以及相应的策略分布 µ(a_t|x_t) 和初始 LSTM 状态通过队列发送给 learner(典型 DRL agent 架构由卷积网络、LSTM、全连接层组成)。然后,learner 会根据从许多 actor 那里收集到的轨迹
批次
不断更新其策略 π。通过这种简单的架构,learner 可以使用 GPU 加速,actor 也可以轻松地分布在多台机器上。然而,在更新时,learner 的策略 π 有可能比 actor 的策略 µ 超前数次,因此 actor 和 learner 之间存在策略滞后。V-trace 可纠正这种滞后现象,在保持数据效率的同时实现极高的数据吞吐量。使用
强化学习
中经典的 actor-learner 架构,可提供与分布式 A3C 类似的容错能力,但由于 actor 发送的是观测数据而非
参数
/ 梯度,因此通常通信开销较低。
神经网络
。
参数
分布在 learner 中,actor 从所有 learner 中并行检索
参数
,同时只向单个 learner 发送观察结果。IMPALA 使用同步
参数
更新,这对于在扩展到多台机器时保持数据效率至关重要。
批次
维度,将卷积网络并行应用于所有输入。同样,一旦计算出所有 LSTM 状态,它还会并行将输出层应用到所有时间步骤。这一优化将有效
批次
规模增加到数千次。通过利用网络结构依赖性和操作融合,基于 LSTM 的 agent 还能显著提高 learner 的速度。最后,还利用了
TensorFlow
中几种现成的优化方法,例如在进行计算的同时为 learner 准备下一批数据,使用 XLA(
TensorFlow
即时编译器)编译计算图的部分内容,以及优化数据格式以获得 cuDNN 框架的最高性能等。
马尔可夫决策过程
(Markov Decision Processes,MDP)中的 discounted infinite-horizon RL 问题,其目标是找到一个能使未来 discount reward 的预期总和最大化的策略 π:


(1)



权重
。在 on-policy 的情况下(当 π = µ 时),假设 c¯≥ 1,则所有 c_i = 1,ρ_t = 1,此时式 (1) 改写为:

权重
c_i 和 ρ_t 起着不同的作用。
权重
ρ_t 出现在 δ_t V 的定义中,并定义了该更新规则的 fixed point。在函数可以完美表示的情况下,这种更新的 fixed point(即所有状态下 V (x_s) = v_s)(δt V 的期望值等于零(在 µ 条件下))是某种策略 πρ¯ 的值函数 V^(π_ρ¯),其定义为:

收敛
到的价值函数的性质,而 c¯ 则影响
收敛
到该函数的速度。

参数
λ∈ [0, 1],方法是设置:

参数
µ 的梯度为:


参数
:

(4)
权重
,以更新方向中的策略
参数
:



参数
表示 V_θ 和当前策略 π_ω。actor 遵循某些行为策略而生成轨迹 μ。v_s 由式 (1) 定义。在训练时间 s,通过对目标 v_s 的 2 次损失的
梯度下降
来更新值
参数
θ,即在如下方向:

参数
ω:

收敛
,可以像在 A3C 中一样,沿着方向添加 entropy bonus:

多任务学习
方面,在新引入的 30 个
DeepMind
实验室任务集和 the Atari 学习环境的全部 57 个游戏上训练 agent— 每个 agent 在所有任务中都使用一组
权重
。在所有实验中,使用了两种不同的模型架构:一种是在策略和价值之前使用 LSTM 的浅层模型(如图 5(左)所示),另一种是更深层的残差模型(如图 5(右)所示)。

图 5. 模型架构。左图:浅层架构,2 个卷积层,120 万个
参数
。右图:深层架构,15 个卷积层和 160 万个
参数
TensorFlow
操作实现,但在概念上与 A3C 中使用的队列类似。表 1 详细列出了采用图 5 中浅层模型的单机版和多机版的结果。在单机情况下,IMPALA 在这两项任务上都取得了最高性能,超过了所有 batched A2C 变体,也超过了 A3C。然而,在分布式多机设置中,IMPALA 才能真正展示其可扩展性。

表 1. 图 5 所示的浅层模型在 seekavoid_arena_01(任务 1)和 rooms keys doors puzzle(任务 2)上的吞吐量。后者有长度可变的 episodes 和缓慢的 restarts。如果没有特别说明,batched A2C 和 IMPALA 使用的批处理大小为 32
批次
。

图 6. 上行:在 5 个
DeepMind
实验室任务上进行单任务训练。每条曲线都是基于最终奖励的最佳 3 次运行的平均值。IMPALA 的性能优于 A3C。下行:不同超
参数
组合的稳定性,按不同超
参数
组合的最终性能排序。IMPALA 始终比 A3C 更稳定
DeepMind
Lab 的 30 种不同任务。在该套件的众多任务类型中,包括带有自然地形的视觉复杂环境、带有基础语言的指令型任务、导航任务、认知任务和以脚本机器人为对手的第一人称标记任务。有关 DMLab-30 和任务的详细介绍,可访问 github.com/deepmind/lab 和 deepmind.com/dm-lab-30。作者将 IMPALA 的多个变体与分布式 A3C 实现进行了比较。除了使用基于群体训练(population based training,PBT)的 agent 外,所有 agent 都在相同范围内进行超
参数
扫描训练。作者报告的是 mean capped humannormalised score,其中每个任务的得分上限为 100%。使用 mean capped humannormalised score 强调了解决多个任务的必要性,而不是专注于在单一任务上成为 super human。对于 PBT,作者使用 mean capped humannormalised score 作为适应度函数,并调整熵成本、
学习率
和 RMSProp ε。
深度残差网络
架构(图 5(右));IMPALA,浅层,210 个 actors;IMPALA,深层,150 个 actors,都只有一个 learner;IMPALA,deep,PBT,与 IMPALA,deep 相同,但额外使用 PBT 进行超<mark data-type=”concepts” data-id=”2e98
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...