










语言模型
的快速发展,其长度外推能力(length extrapolating)正日益受到研究者的关注。尽管这在 Transformer 诞生之初,被视为天然具备的能力,但随着相关研究的深入,现实远非如此。传统的 Transformer 架构在训练长度之外无一例外表现出糟糕的推理性能。
插值
(PI)(Chen et al., 2023),reddit 网友给出的 NTK-aware Scaled RoPE (bloc97, 2023),都在试图让模型真正具备理想中的外推能力。
人工智能
团队最新研究表明,这一被忽视的角色,极有可能成为扭转局势的关键。Transformer 糟糕的外推性能,除了位置编码外,self-attention 本身仍有诸多未解之谜。
人工智能
团队自研了新一代
注意力机制
,在实现长度外推的同时,模型在具体任务上的表现同样出色。

-
论文地址:https://arxiv.org/abs/2309.08646
-
Github仓库:https://github.com/codefuse-ai/Collinear-Constrained-Attention
-
ModelScope:https://modelscope.cn/models/codefuse-ai/Collinear-Constrained-Attention/summary
-
HuggingFace:敬请期待
背景知识
长度外推 (Length Extrapolating)
语言模型
在处理比其训练数据中更长的文本时的能力。在训练大型
语言模型
时,通常有一个最大的序列长度,超过这个长度的文本需要被截断或分割。但在实际应用中,用户可能会给模型提供比训练时更长的文本作为输入,如果模型欠缺长度外推能力或者外推能力不佳,这将导致模型产生无法预期的输出,进而影响模型实际应用效果。
自注意力
(Self-Attention)
语言模型
的内核,对于推动
人工智能
领域的发展起到了举足轻重的作用。这里以下图 1 给出形象化的描述,这项工作本身已经被广泛认可,这里不再进行赘述。初次接触大
语言模型
,对这项工作不甚了解的读者可以前往原论文获取更多细节 (Vaswani et al., 2017)。

图1. 多头
注意力机制
示意图,引自(Vaswani, et al., 2017)。
位置编码 (Position encoding)
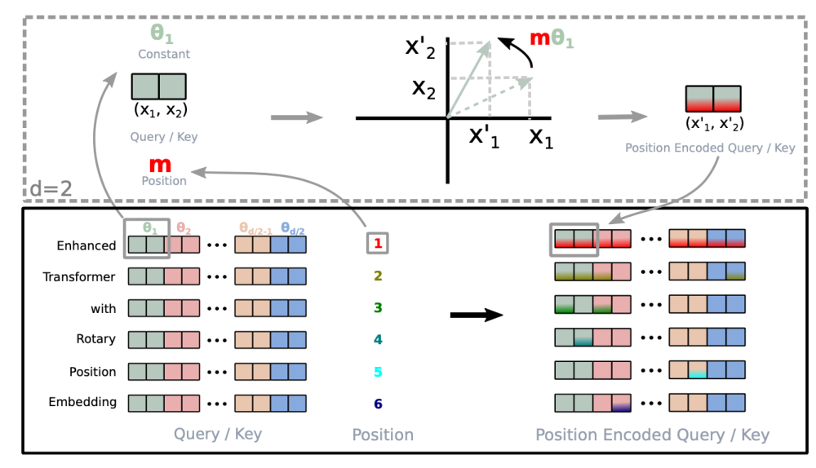
图2. 旋转位置编码结构,引自(
Su et al., 2021
)。
位置
插值
(Position Interpolation)
插值
仍然离不开微调,实验表明,即使是宣称无需微调便可外推的 NTK-aware Scaled RoPE,在传统 attention 架构下,至多只能达到 4~8 倍的外推长度,且很难保障良好的语言建模性能和长程依赖能力。

图3. 位置
插值
示意图,引自(
Chen et al., 2023
)。
CoCA
人工智能
团队近期发现了一个久被忽视的关键:要从根本上解决 Transformer 模型的外推性能问题,self-attention 机制同样需要重新考量。
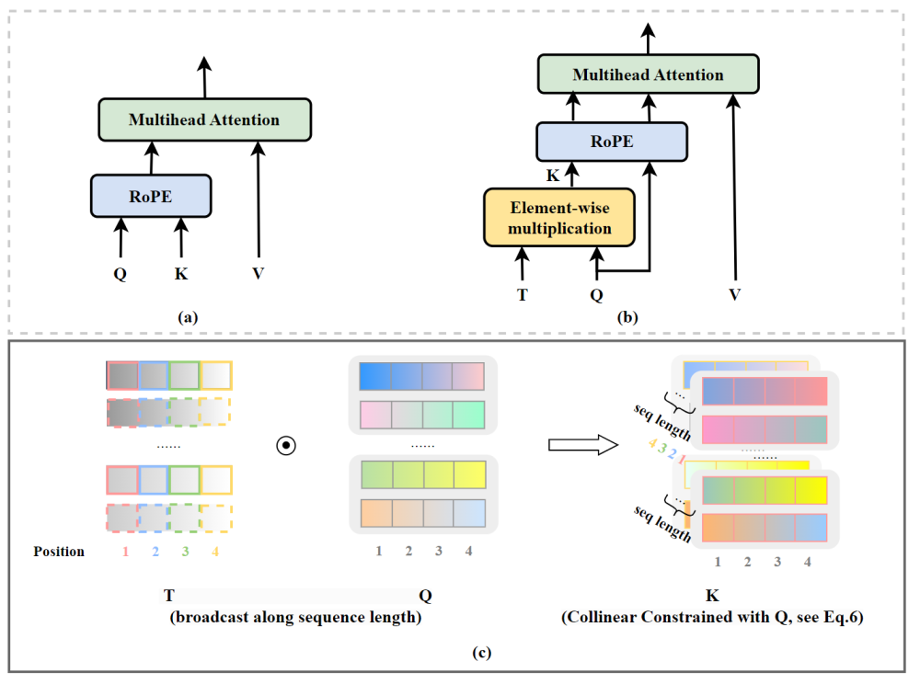
图4. CoCA 模型架构,引自(
Zhu et al., 2023
)。
RoPE 与 self-attention 的异常行为
注意力机制
使用这些关系来决定模型应该 “关注” 输入序列中的哪些部分。
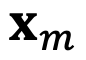
和
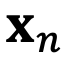
,分别代表输入序列中的m个和第n个位置索引对应的 token,其 query 和 key 分别为
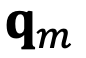
和
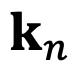
。它们之间的注意力可以表示为一个函数
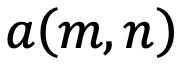
,如果应用 RoPE,则可以进一步简化为仅依赖于m和n相对位置的函数
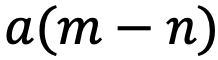
。
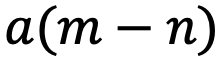
可以解释为
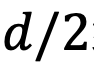
组复数(
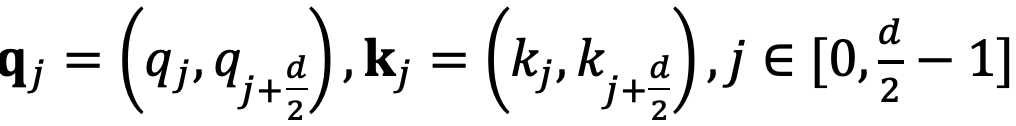
,其中d为 hidden dimension 维度,省略位置索引m,n)经过旋转后的内积之和。这在直觉上是有意义的,因为位置距离可以建模为一种序,并且两个复数的内积随着旋转角度
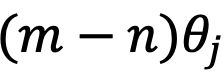
的变化而变化,以图 5 为例,其中
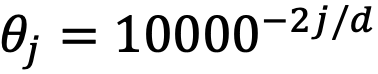
,
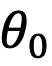
为
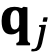
和
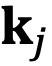
的初始夹角。
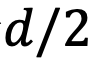
组复数中的任意一组
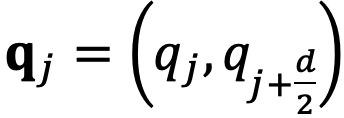
,
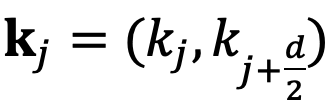
,它们分别具有位置索引m和n。
的角度
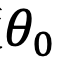
逆时针从
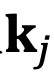
旋转到
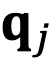
,那么它们的位置关系有两种可能的情况(不考虑 =,因为它是平凡的)。
-
正常保序关系
:当

时,如图 5 右侧所示。注意力分数随着位置距离的增加而降低(直到它们相对角度超出
,超出
的这部分在原论文附录中进行了讨论 (Zhu et al., 2023))。
-
异常行为
:然而,当
时,如图 5 左侧所示,异常行为打乱了
个最邻近的 token 的序。当
时,
和
之间的相对角度将随着
的增大而减小,这意味着最接近的 token 可能会获得较小的注意力分数。(我们在这里使用 “可能”,因为注意力分数是
个内积的总和,也许其中一个是微不足道的。但是,后续实验证实了这一重要性。)并且,无论应用 PI 还是 NTK-aware Scaled RoPE,均无法消除这一影响。

图5.双向模型中的序被破坏,引自(Zhu et al., 2023)。

的角度
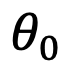
从
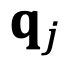
逆时针旋转到
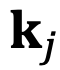
时,而不是从

到
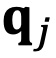
。

图6.因果模型中的序被破坏,引自(Zhu et al., 2023)。
共线约束注意力(CoCA)
-
稳定的远程衰减特性
:CoCA 相对于 RoPE 显示出了更为稳定的远程衰减特性。
-
显存瓶颈与解决方案
:CoCA 有引入显存瓶颈的风险,但论文给出了十分高效的解决方案,使得 CoCA 的计算和空间复杂度几乎与最初版本的 self-attention 无异,这是十分重要的特性,使得 CoCA 的实用性十分优异。
-
无缝集成
:CoCA 可以与当前已知的
插值
手段(论文中实验了 NTK-aware Scaled RoPE)无缝集成,且在无需微调的情况下取得了远超原始 attention 结构的性能,这意味着使用 CoCA 训练的模型,天然就拥有近乎无限的外推能力,这是大
语言模型
梦寐以求的特性。
实验结论
-
Origin:原始 attention 结构,位置编码方式为 RoPE
-
ALibi:原始 attention 结构,位置编码方式为 ALibi
-
CoCA:论文模型结构,位置编码方式为 RoPE
长文本建模能力

图7.滑动窗口困惑度测试结果,引自(
Zhu et al., 2023
)。
捕捉长程依赖
语言模型
预测下一个 token 的熟练程度的指标。然而,它并不能完全代表一个理想的模型。因为虽然局部注意力在困惑度上表现出色,但它在捕获长程依赖性方面往往表现不佳。
准确率
就开始迅速下降,最终下跌至 10% 以下。相比之下,即使测试序列长度扩展到原始训练长度的 16 倍,CoCA 也始终表现出很高的准确性,在 16 倍外推长度时仍然超过 60%。比 Origin 模型整体高出 20%,而比 ALibi 整体高出 50% 以上。

图8.随机密钥识别检索性能曲线,引自(Zhu et al., 2023)。
超参数
稳定性
超参数
稳定性进行了深入探讨。
准确率
,而 Origin 模型在 scaling factor=8 时,
准确率
下跌至了 20% 以下。更进一步,从 Table 5 的明细数据可以看出,Origin 模型即使在表现最好的 scaling factor=2 时,仍然与 CoCA 模型有 5%~10% 的
准确率
差距。

图9. Origin model 和 CoCA 在不同 scaling factor 的困惑度,引自(Zhu et al., 2023)

图10. Origin 模型和 CoCA 在不同 scaling factor 的通行密钥准确性,引自(Zhu et al., 2023)

长度外推中的注意力得分
语言模型
在长度外推中的失败与注意力得分的异常值(通常是非常大的值)直接相关。论文进一步探讨了这一现象,这一现象也从侧面说明了为什么 CoCA 模型在长度外推中的表现要优于传统 attention 结构。
-
从 (a1) 和 (b1) 可以发现,Origin 模型的注意力得分存在少量异常值,数值比 CoCA 模型注意力得分大 10~20 倍。
-
由于这些异常值影响了观察效果,(a2) 局部放大了最后 500 个 token,可以看到 Origin 模型的 last layer 注意力得分几乎为 0,这说明 Origin 模型在长度外推时,发生了关注邻近 token 的失效。
-
从 (b2) 可以看出,当应用动态 NTK 方法后,Origin 模型在邻近 token 处的注意力得分变得异常大,这一异常现象与前文论证的 RoPE 与 self-attention 的异常行为息息相关,Origin 模型在邻近 token 处可能存在着严重的
过拟合
。
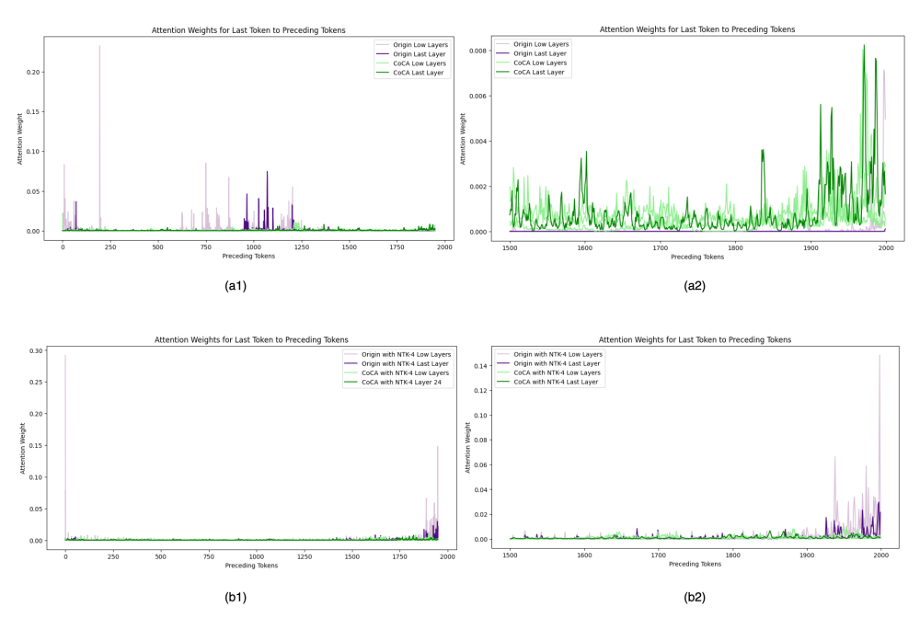
图11. 外推中的注意力得分,引自(Zhu et al., 2023)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...