
编辑 | 萝卜皮
凭借其复杂的排列和动态功能,蛋白质通过采用简单构建块的独特排列(其中几何形状是关键)来执行大量的生物任务。将这个几乎无限的排列库转化为各自的功能,可以方便研究人员设计用于特定用途的定制蛋白质。
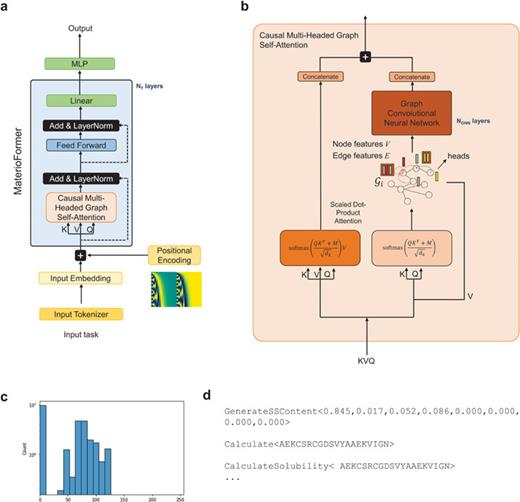
麻省理工学院(MIT)的 Markus Buehler 提出了一种灵活的基于语言模型的深度学习策略,将 Transformer 与图神经网络结合起来,以更好地理解和设计蛋白质。
「通过这种新方法,我们可以通过对基本原理进行建模,利用大自然发明的一切作为知识基础。」Buehler 说,「该模型重新组合了这些自然构建块,以实现新功能并解决这些类型的任务。」
该模型用于预测二级结构含量(每个残基水平和总体含量)、蛋白质溶解度和测序任务。在逆向任务上进一步训练,该模型能够设计具有这些特性作为目标特征的蛋白质。模型被制定为一个通用框架,完全基于提示,并且可以适应各种下游任务。
该研究以「
Generative pretrained autoregressive transformer graph neural network applied to the analysis and discovery of novel proteins
」为题,于 2023 年 8 月 29 日发布在《
Journal of Applied Physics
》。

多尺度建模为分层生物材料的分析和设计提供了强大的基础。特别关注构成众多生物和生物衍生材料基础的蛋白质材料。在该分析领域,使用机器学习和相关方法的数据驱动建模已成为一种强大的策略,其中包括分析任务(例如从序列预测属性)和逆向设计任务(设计蛋白质或其他生物材料以满足一组目标特性)。
具体来说,生成生物材料科学是材料发现的新兴前沿,已应用于蛋白质、有机分子、无机物(包括药物设计)、生物活性材料和建筑材料等;最近,由于语言模型的使用,促进了生物蛋白质材料多尺度建模的发展。
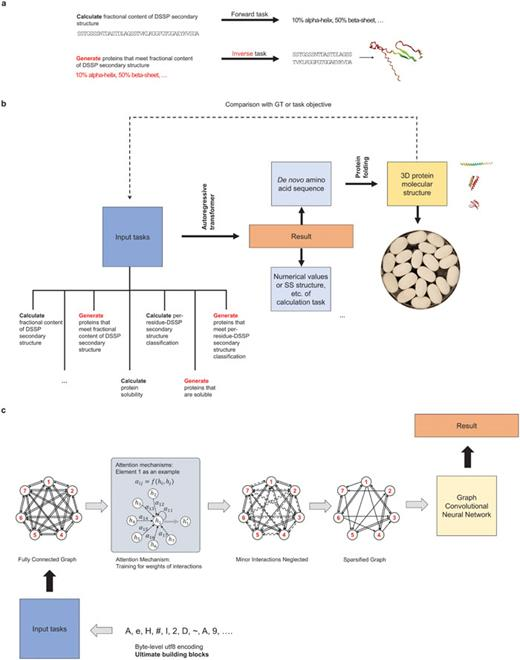
麻省理工学院的研究人员开发了一种灵活的基于语言模型的深度学习策略,应用于解决蛋白质建模中的复杂正向和逆向问题;基于注意力神经网络,将 Transformer 和图卷积架构集成到因果多头图机制中,从而实现生成预训练模型 MaterioFormer。该模型能够在端到端序列到特性预测的范围内分析蛋白质序列,并生成分子蛋白质结构以满足各种目标特性,所有这些都在一个模型中完成。
该团队证明,生成语言方法为蛋白质材料的发现和设计提供了一个灵活的平台。研究人员可以轻松地将这些模型整合到广泛的应用程序中并解决多个复杂的任务。
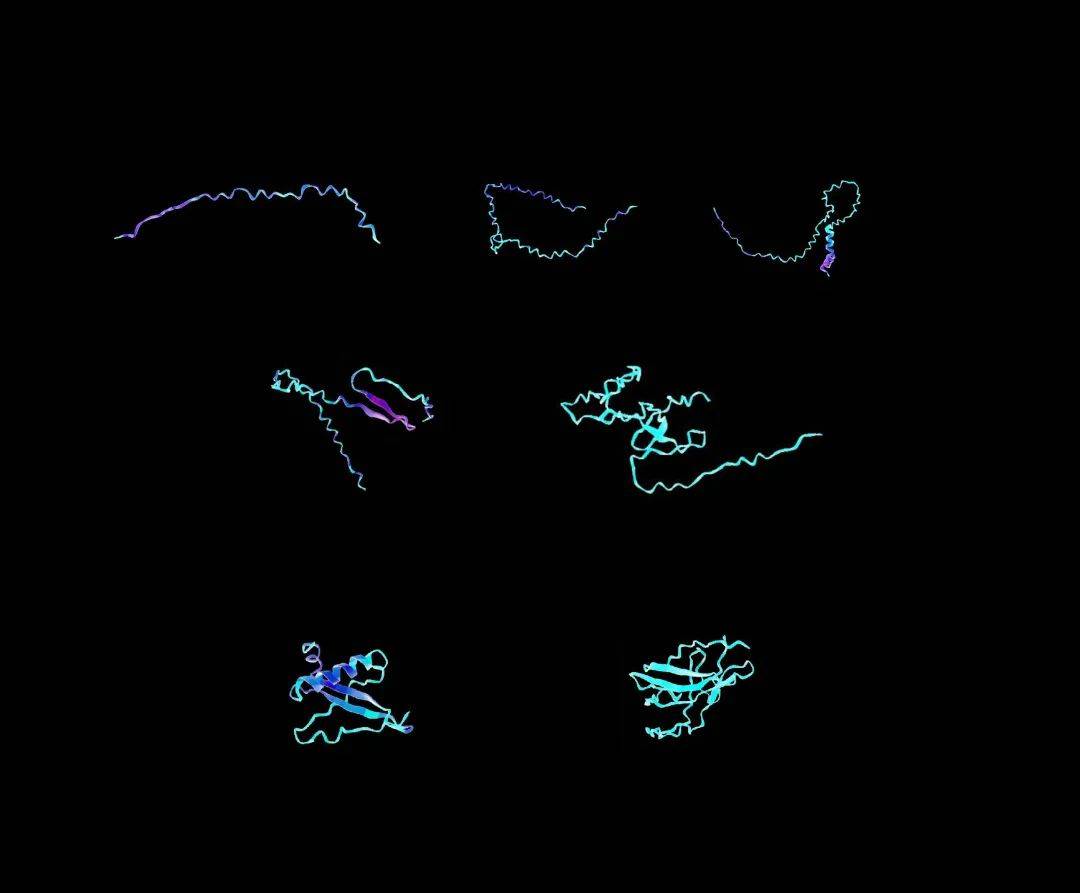
图示:MaterioFormer 模型概述,这是一种基于文本提示输入构建的自回归变换图卷积模型,适用于各种任务。(来源:论文)
虽然该模型总体上很好地解决了多个任务,但使用一次专注于一项任务的专用模型仍然有一定的优势(例如,序列到属性的预测或使用扩散模型的生成任务)。例如,在创建满足特定每个残基二级结构的蛋白质序列的设计任务中,MaterioFormer 有时无法准确反映预测中所需的长度。当从输入蛋白质序列进行二级结构预测时,会看到类似的情况。
相比之下,仅针对一项生成任务训练的扩散模型在序列长度方面可以更准确地解决该问题。值得关注的是,已有的从整体二级结构内容生成序列的模型,很难识别新的蛋白质设计,而 MaterioFormer 可以非常好地解决这项任务,具有非常高程度的新颖蛋白质序列设计。
MaterioFormer 模型的一个吸引人的方面是灵活的迭代工作流程,可以集成人类智能和人工智能。人们可以输入提示,设计蛋白质,并检查它是否适合设计标准(如果不适合,则重新采样或调整设计参数),然后在辅助任务中使用输出。这种迭代过程还可以轻松地与自主实验相结合,为数据生成、收集和进一步训练模型提供额外的来源。

从更理论的角度来看,这里解决的问题是一个复杂的积木组装问题——积木不仅是氨基酸残基、二级结构,而且是组合这些众多组合空间的数字和各种任务。值得注意的是,这里使用的策略学习了基础和可转移的见解。这产生了大量的条件蛋白质设计以及正向和反向任务解决方案。通过更多的数据,预计可以捕获高度复杂的现象。
虽然二级结构预测通常很好,尤其是总体二级结构比率,但与专用溶解度模型相比,溶解度预测的准确性仍然相对较低。然而,对于 <64 个残基的短序列,准确率达到 0.77。这项任务仅在一小部分~4,000个序列溶解度对(蛋白质长度<128)上进行训练(相对于整个序列数据集中的 40 000 个序列,所有长度高达~1700)。通过更深的模型和更多的预训练,对于长达 512 个氨基酸的序列,溶解度准确度高达 78%,显示出这里开发的方法在扩展可用性、准确性和通用性方面的巨大潜力。未来的工作可以扩展模型的训练任务,从而考虑更长序列的任务和预测。
这里使用的训练策略由基于文本的提示组成,非常灵活,可以轻松适应各种任务。此外,由于该团队训练和预测编码为文本的数字,因此研究人员不必专门对数值进行专门编码。这对于任务和预测开发都有帮助,并且可以允许在架构中封装高维数据。还有机会引入交叉注意力机制,从而对注意力层和图层中处理的信息进行更复杂的合并。
未来的探索可以在正向和反向方向上纳入额外的预测任务,并扩展训练集以纳入更多序列(例如,在预训练阶段)。探索与不同生物分子(例如 mRNA 或 DNA)的相互作用也很有趣,由于灵活的字节级分词器,这些分子可以添加到任务训练中。
此类训练任务还可能具有多尺度问题,例如不仅编码构成蛋白质或生物分子,还编码其他特征,例如相对浓度、pH 或盐浓度等。这最终可能用于构建多模态多尺度模型,该模型可以将从不同的模拟和实验范式中开发的知识融入到从预训练到任务的所有训练阶段。
该研究中使用的多尺度方案捕获了物质的基本构建块与所得属性之间的复杂新关系。因此,它提供了一种协同学习能力,可以表达嵌入基础知识中的一组潜力,用于训练利用未知或鲜为人知的交叉关系的模型。从机制上讲,使用一组以复杂分层模式排列的通用构建块来创建紧急功能的方法的基本设计促进了这一点。
「一个很大的惊喜是,尽管该模型是为了能够解决多个任务而开发的,但它的表现却异常出色。这可能是因为该模型通过考虑不同的任务学到了更多东西。」他说,「这一变化意味着,研究人员现在可以广泛地思考多任务和多模式模型,而不是为特定任务创建专门的模型。」
「虽然我们目前的重点是蛋白质,但这种方法在材料科学中具有巨大的潜力。」Buehler 说,「我们特别热衷于探索材料失效行为,旨在设计具有特定失效模式的材料。」
论文链接:
https://pubs.aip.org/aip/jap/article/134/8/084902/2908328/Generative-pretrained-autoregressive-transformer
相关报道:
https://phys.org/news/2023-08-neural-network-brand-proteins.html
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...