
从毫无存在感到无人不谈,大型语言模型(LLM)的江湖地位在这几年发生了巨变。这个领域的发展令人目不暇接,但也正因如此,人们难以了解还有什么难题有待解决以及哪些领域已有成熟应用。


图 1:LLM 挑战概况。LLM 的设计与部署前做出的决策有关。LLM 行为方面的挑战发生在部署阶段。科学方面的挑战会阻碍学术进步。
挑战
难以理解的数据集
-
有许多非常相近几乎算是重复的数据;
-
基准数据遭受污染;
-
某些信息可用于识别个人的身份;
-
预训练的数据域混在一起;
-
微调任务混在一起的情况难以处理。

表 1:所选预训练数据集概况
依赖 token 化器

图 2:依赖 token 化器的典型缺点。(1) token 化器的训练步骤涉及到复杂繁琐的计算,比如多次遍历整个预训练数据集,并且还会导致对预训练数据集的依赖,这在多语言环境中是个尤其麻烦的问题。(2) LLM 的嵌入层 E 和输出层 W 与词汇量有关,比如在 T5 模型中词汇占到了模型参数数量的 66% 左右。
预训练成本高

图 3:掩码策略。每一行表示一个特定输出 y_i(行)可以考虑哪些输入 x_i(列)(红色表示单向,蓝色表示双向)。

图 4:根据预训练目标进行自监督式的数据构建,来自 Tay et al.
微调开销

图 5:针对下游具体任务对 LLM 进行微调。(a) 展示了简单普通的微调,这需要更新整个模型,从而为每个任务生成一个新模型。(b) 展示了 PEFT 方法,其为每个任务学习一个模型参数子集,然后配合固定的基础 LLM 使用。针对不同任务执行推理时,可以复用同一个基础模型。
推理延迟高
上下文长度有限
prompt 不稳定

图 6:所选的 prompt 设计方法概况,分为单轮和多轮 prompt 设计。
幻觉问题

图 7:GPT-4 的幻觉问题示例,访问日期:02/06/2023。

图 8:用户与 LLM 互动时的 a) 内在和 b) 外在幻觉示例。示例 a) 中,LLM 给出的答案与给定上下文相矛盾,而在 b) 中,上下文没有提供足够信息,无法知道生成的答案是否相矛盾。

图 9:检索增强型 GPT-4 示例,这是幻觉问题的一种潜在解决方法,访问日期:02/06/2023。
行为不对齐

图 10:对齐。这里将对齐方面的现有研究工作分为两类:检测未对齐的行为和实现模型对齐的方法。
过时的知识

图 11:知识过时问题的解决方法有:S.1) 通过对基础检索索引使用热交换,使其获得最新知识,从而增强检索能力;S.2) 通过应用模型编辑技术。
评估方法不稳定
基于静态的、人工编写的 Ground Truth 来执行评估
难以分辨生成的文本和人类编写的文本
无法通过模型或数据扩展解决的任务
缺乏实验设计
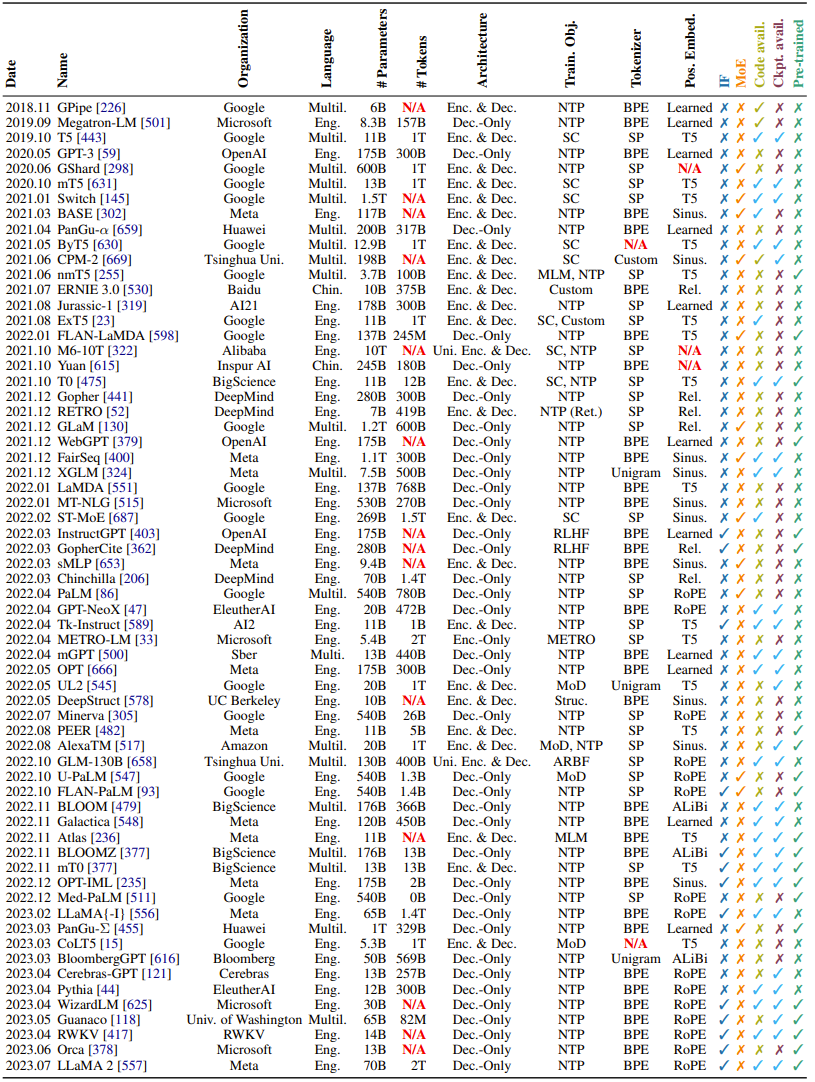
表 2:所选 LLM 概况。N/A 表示细节缺失。对于研究了多种模型大小的论文,这里仅给出了最大的模型。对于 Tokenizer 项为 SP 的论文,研究者表示无法从相应论文中得知使用的是 BPE 还是 Unigram token 化方法。
难以复现
应用

图 12:LLM 应用概况。不同颜色表示不同的模型适应程度,包括预训练、微调、提示策略、评估。
聊天机器人
计算生物学
计算机编程

图 13:API 定义框架。这张示意图展示了一个 API 定义框架:为了解决特定任务,可以在 prompt 中提供一个通用的 API 定义,从而让 LLM 可以使用外部代码或工具。这种方法的扩展包括要求 LLM 实现 API 定义中的功能(红色),以及提示 LLM 自己去调试任何不执行的 API 代码(绿色)。
创意工作

图 14:模块化 prompt 设计。通过一系列分立的 prompt 和处理步骤,LLM 可以执行无法放入单个上下文窗口中的任务以及解决无法通过单一 prompt 步骤解决的任务。
知识工作
法律
医学
推理
机器人和具身智能体
社会科学和心理学

图 15:LLM 在社会科学和心理学领域的用例。
生成合成数据
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...