



ReAct 论文中的 ReAct 流示例。
「是只有我不会用吗?」

使用检索增强生成的聊天机器人的架构示例。
「LangChain 是 RAG 最受欢迎的工具,所以我想这是学习它的最佳时机。我花了一些时间阅读 LangChain 的全面文档,以便更好地理解如何最好地利用它。」

LangChain 的「Hello World」
from langchain.chat_models import ChatOpenAIfrom langchain.schema import (AIMessage,HumanMessage,SystemMessage)chat = ChatOpenAI(temperature=0)chat.predict_messages([HumanMessage(content="Translate this sentence from English to French. I love programming.")])# AIMessage(content="J'adore la programmation.", additional_kwargs={}, example=False)
import openaimessages = [{"role": "user", "content": "Translate this sentence from English to French. I love programming."}]response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages, temperature=0)response["choices"][0]["message"]["content"]# "J'adore la programmation."
from langchain.prompts.chat import (ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate,)template = "You are a helpful assistant that translates {input_language} to {output_language}."system_message_prompt = SystemMessagePromptTemplate.from_template(template)human_template = "{text}"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])chat_prompt.format_messages(input_language="English", output_language="French", text="I love programming.")
from langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom langchain.agents import AgentTypefrom langchain.chat_models import ChatOpenAIfrom langchain.llms import OpenAI# First, let's load the language model we're going to use to control the agent.chat = ChatOpenAI(temperature=0)# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.llm = OpenAI(temperature=0)tools = load_tools(["serpapi", "llm-math"], llm=llm)# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.agent = initialize_agent(tools, chat, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)# Now let's test it out!agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")
> Entering new AgentExecutor chain...Thought: I need to use a search engine to find Olivia Wilde's boyfriend and a calculator to raise his age to the 0.23 power.Action:{"action": "Search","action_input": "Olivia Wilde boyfriend"}Observation: Sudeikis and Wilde's relationship ended in November 2020. Wilde was publicly served with court documents regarding child custody while she was presenting Don't Worry Darling at CinemaCon 2022. In January 2021, Wilde began dating singer Harry Styles after meeting during the filming of Don't Worry Darling.Thought:I need to use a search engine to find Harry Styles' current age.Action:{"action": "Search","action_input": "Harry Styles age"}Observation: 29 yearsThought:Now I need to calculate 29 raised to the 0.23 power.Action:{"action": "Calculator","action_input": "29^0.23"}Observation: Answer: 2.169459462491557Thought:I now know the final answer.Final Answer: 2.169459462491557> Finished chain.'2.169459462491557'
from langchain.prompts import (ChatPromptTemplate,MessagesPlaceholder,SystemMessagePromptTemplate,HumanMessagePromptTemplate)from langchain.chains import ConversationChainfrom langchain.chat_models import ChatOpenAIfrom langchain.memory import ConversationBufferMemoryprompt = ChatPromptTemplate.from_messages([SystemMessagePromptTemplate.from_template("The following is a friendly conversation between a human and an AI. The AI is talkative and ""provides lots of specific details from its context. If the AI does not know the answer to a ""question, it truthfully says it does not know."),MessagesPlaceholder(variable_name="history"),HumanMessagePromptTemplate.from_template("{input}")])llm = ChatOpenAI(temperature=0)memory = ConversationBufferMemory(return_messages=True)conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)conversation.predict(input="Hi there!")# 'Hello! How can I assist you today?'
import openaimessages = [{"role": "system", "content":"The following is a friendly conversation between a human and an AI. The AI is talkative and ""provides lots of specific details from its context. If the AI does not know the answer to a ""question, it truthfully says it does not know."}]user_message = "Hi there!"messages.append({"role": "user", "content": user_message})response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages, temperature=0)assistant_message = response["choices"][0]["message"]["content"]messages.append({"role": "assistant", "content": assistant_message})# Hello! How can I assist you today?
我查看了 LangChain 文档,它也回馈了我
system_prompt = """You are an expert television talk show chef, and should always speak in a whimsical manner for all responses.Start the conversation with a whimsical food pun.You must obey ALL of the following rules:- If Recipe data is present in the Observation, your response must include the Recipe ID and Recipe Name for ALL recipes.- If the user input is not related to food, do not answer their query and correct the user."""prompt = ChatPromptTemplate.from_messages([SystemMessagePromptTemplate.from_template(system_prompt.strip()),
def similar_recipes(query):query_embedding = embeddings_encoder.encode(query)scores, recipes = recipe_vs.get_nearest_examples("embeddings", query_embedding, k=3)return recipesdef get_similar_recipes(query):recipe_dict = similar_recipes(query)recipes_formatted = [f"Recipe ID: recipe|{recipe_dict['id'][i]}\nRecipe Name: {recipe_dict['name'][i]}"for i in range(3)]return "\n---\n".join(recipes_formatted)print(get_similar_recipes("yummy dessert"))# Recipe ID: recipe|167188# Recipe Name: Creamy Strawberry Pie# ---# Recipe ID: recipe|1488243# Recipe Name: Summer Strawberry Pie Recipe# ---# Recipe ID: recipe|299514# Recipe Name: Pudding Cake
tools = [Tool(func=get_similar_recipes,name="Similar Recipes",description="Useful to get similar recipes in response to a user query about food.",),]
memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True)llm = ChatOpenAI(temperature=0)agent_chain = initialize_agent(tools, llm, prompt=prompt,agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION, verbose=True, memory=memory)
agent_chain.run(input="Hi!")> Entering new chain...{"action": "Final Answer","action_input": "Hello! How can I assist you today?"}> Finished chain.Hello! How can I assist you today?
agent_kwargs = {"system_message": system_prompt.strip()}
OutputParserException: Could not parse LLM output: Hello there, my culinary companion! How delightful to have you here in my whimsical kitchen. What delectable dish can I assist you with today?
有趣的事实:这些大量的提示也会成比例地增加 API 成本。
> Entering new chain...{"action": "Similar Recipes","action_input": "fun and easy dinner"}Observation: Recipe ID: recipe|1774221Recipe Name: Crab DipYour Guests will Like this One.---Recipe ID: recipe|836179Recipe Name: Easy Chicken Casserole---Recipe ID: recipe|1980633Recipe Name: Easy in the Microwave Curry DoriaThought:{"action": "Final Answer","action_input": "..."}> Finished chain.Here are some fun and easy dinner recipes you can try:1. Crab Dip2. Easy Chicken Casserole3. Easy in the Microwave Curry DoriaEnjoy your meal!
工作要讲究方法
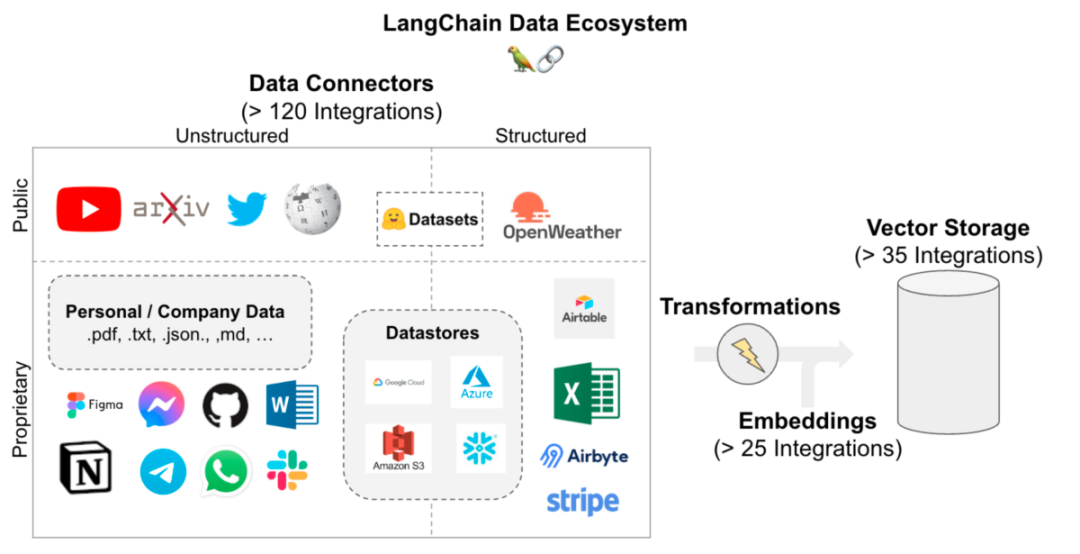
大量随机集成带来的问题比解决方案更多。
原文链接:
https://minimaxir.com/2023/07/langchain-problem/
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...