

由于没有足够的点来描述不同小物体的特征,导致深度网络在小物体或距离摄像头很远的物体上效果不佳。这个问题在图像识别中颇为本质,因为无论什么相机或者其它的视觉传感器,都无法避免 「近大远小」—— 对于近处的物体,传感器返回的采样点(像素)多,而对于远处的物体,采样点(像素)较少。因此识别远处物体天然就比较困难。然而标准模型中频繁的下采样实际上让远处或者小物体上的点更加的少了, 从而加剧了这种困难。
目前主流的解决方案是:1)提高图像分辨率;2)增加模型参数量。这两种方案让图像在多次下采样后拥有更多的点,而更多的参数量允许在每个点上存储更多的信息 — 如多个物体的特征信息。然而,这两种方案均会极大的增加网络的计算量,减慢物体识别的速度,同时,大量无意义的计算被浪费在了大物体表面那些均匀单一,毫无特征的部分。
即使在主流图像识别已经全面转向 Transformer 的时代,传统栅格和均匀下采样仍在图像识别网络中大量使用,这大概是因为简单的均匀下采样易于实现(例如使用 strided convolution),而且基于栅格的结构利用在 GPU 上计算。然而,栅格结构实际上阻碍了更加高效的分配计算量的方式,并且导致了上述识别小物体和远处物体问题只能用 brute-force 的方法来解决。即使文献中有很多效果很好的基于 deformable convolution 或 deformable attention 的方案,它们还是受限于图像的栅格表示形式,导致经常还要把图像转换回栅格形式以进行下采样和上采样的操作。
认识到传统栅格带来的问题,可供考虑的另一种方案是采用更加灵活的点云的形式来储存图像特征。点云的形式允许图像在不同部分使用不同的密度,从而在无特征大平面上减少采样点,而在远处或小物体聚集的区域多保留采样点。然而,由于点云的表示形式和主流的栅格完全不同,改用点云形式的图像识别方案面临很多问题,如,如何划分点云上的邻域?如何学习一种自适应的下采样方式来实现上述的功能?如何处理不同区域邻域尺度不同的问题?如何解码?
苹果公司和俄勒冈州立大学的研究者们提出了一套完整的使用点云进行图像分割的方案,解决了上述的诸多问题,并提出了可以根据图像分割的损失函数进行端到端学习的下采样算法、局部注意力 Transformer 层和基于点云的 Transformer 解码器(decoder)。

-
论文地址:https://arxiv.org/abs/2304.12406
-
代码地址:https://github.com/apple/ml-autofocusformer
他们在 ADE20K 和 Cityscapes 数据集上达到了胜于普通栅格算法的效果,尤其是在很难并有很多远处小物体的 Cityscapes 数据集上,仅用一个 42.6M 参数的小模型就超过了 SOTA 算法 Mask2Former 使用 197M 参数大模型的效果。在 PapersWithCode 排名中,AutoFocusFormer-Base 模型在 Instance Segmentation benchmark 中超过了所有未使用 Mapillary Vista 额外训练数据的 Large 或更大的模型:

模型
这篇论文所提出的 AutoFocusFormer 模型,是一款基于 Transformer 的自适应模型。通过多次自适应下采样,可以迅速将高分辨率的图像精简为少量的特征点云,并且,模型会自动根据任务目标(损失函数)来调整在图像不同区域内的采样密度,从而生成的特征点云会在信息量丰富的区域更加稠密,而在不那么重要的区域稀疏。
之前的数种基于 Transformer 的自适应模型(如 AdaViT,DynamicViT,A-ViT)通常采用 global attention,即在 self-attention 中,所有 token 都会去 attend 其它所有 token,而这带来的二次复杂度,使模型无法高效应用于高分辨率的图像分割任务中。这些方法通过训练一个可导的 binary mask 来区分 「重要」 和 「不重要」 的 token,从而在模型推论中舍弃那些获值为零的点。然而,由于梯度无法传导,这些方法无法在训练过程中进行连续多次的下采样。并且,这些方法还需要额外的损失函数来限制 mask 的大小。
而 AutoFocusFormer 的设计成功规避了这些缺点:AFF 使用局部注意力(local attention),将每个 token 的 attention 限制在固定大小的邻域上;AFF 使用了一个全新的 neighborhood merging 的方法,得以在训练过程中真正的学习自适应下采样;AFF 除了任务本身的损失函数,不需要任何其它指导。因此,AutoFocusFormer 是第一款能够在高分辨率输入上运行的,适合用来执行如图像分割一类像素级预测任务的自适应下采样模型。
下图展示 AFF 的模型框架结构。AFF 由两个卷积层组成的 patch embedding 开始,经由四个阶段(stage),最后由图像分类或者分割解码器输出预测结果。每个 stage 都分为三个模块:平衡聚类(balanced clustering),局部注意力(local-attention) blocks,与自适应下采样(adaptive downsampling)。其中,最重要的是创新的自适应下采样模块。

1. 均匀聚类(balanced clustering)
AFF 采用 local attention,意为每个点只能 attend 它邻域内的 K 个邻居点,以此减少在高分辨率情况下的计算复杂度。因此,比起 global attention,模型需要额外首先为每个点定义邻域。在点云上,传统方法为 K 近邻(K-nearest neighbors),即根据欧氏距离找到离每个点最近的 K 个点,然后把它们的集合定义为此 token 的邻域。然而, KNN 算法在高分辨率图像上效率不高。作者们受到一些高效 KNN 算法的启发,首先将点云划分为大小均等的(小)聚类(例如 8 个点),然后再将每个点的邻域定义为离它最近的 R 个聚类(如 6 个聚类)。由于聚类大小均等,每个 token 都拥有相等数量的邻居,因此不需要使用 zero-padding 浪费 GPU 的内存。另外,由于每个 token 的邻域互有重叠,信息可以顺利地传导到整个图像上,从而不需要像 Swin 模型那样交替切换邻域位置,从而高效解决了寻找邻域的问题。
为保证每个聚类中的点数相等,作者们在文章中提出一个创新的均匀聚类算法。传统的聚类算法,如 k 均值和局部敏感哈希 (locality-sensitive hashing) 都需要多轮迭代,并且都不保证每个 cluster 大小均等。大小不均等的 cluster 会导致邻域大小也不同,从而造成内存上的浪费。而 AFF 使用的方法无需任何迭代,并且保证 cluster 大小相同。此方法首先使用一条空间填充曲线 (space-filling curve)(如,Hilbert curve)将 2D 画面上的所有 token 连成一个 1D array,然后再直接将这个 array 剪切成目标数量的聚类。这样可以保证每个聚类中的样本数严格相等。只不过,简单地用曲线连接 token,将会导致生成的 cluster 在各个方向上的周长不够均等。据此,作者们提出空间填充锚(space-filling anchor)的概念,用作 token 和填充曲线之间的缓冲结构。具体方法见 AFF 的文章。
2. 局部注意力
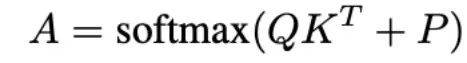
然而,仅仅根据 x 和 y 坐标的差值得出的位置编码并不具备尺度不变性和旋转不变性。这在基于栅格的局部注意力模型中不是问题,因为邻域的大小永远相同。然而,基于点云的邻域可能在不同位置和不同图像中尺度不同。此时,模型将无法泛化到大小不同的同一个物体,或者经过旋转的同一个物体。因此,作者们将相对位置信息扩展到包括两个 token 之间的距离,cosine 和 sine 值:

注意,距离有旋转不变性,而 cosine 和 sine 值有尺度不变性。因此,深度模型能通过这种位置编码,自由地学习选择它需要使用的信息,从而取得更大灵活性。
3. 自适应下采样(adaptive downsampling)
作为每个阶段的最后一个模块,自适应下采样负责将 token 数量减少至原来的 x%。传统的 stride-2 下采样会将数量减少至 1/4,而 AFF 更为灵活的点云结构则对 x% 的值没有限制。实验中,作者们展示了采取 1/4 和 1/5 下采样率的模型的训练结果。
AFF 的自适应下采样模块分为三步:1. 计算重要性分数,2. 根据重要性选择合并中心(merging center),3. 合并邻域(neighborhood merging)。最后一步如下图所示。

第一步中,模型将每个 token 的特征矢量(feature vector)输入一个全连接层,再经过 sigmoid 函数,得到一个处于 0 到 1 之间的重要性分数。然后,拥有最高 「重要性」 的 x% 个 token 被选出,作为下一步中的 merging center。最后,模型使用一个 PointConv 层,将每一个被选取的 token 的邻域内所有的特征矢量合并成为一个全新矢量:

注意,在合并过程中,PointConv 层中的每个邻居点的权值(convolution weights)都经由各自的 「重要性分数」(importance score)调制。若一个 token 的重要性接近于 0,那么它的特征矢量将不会对合并后的矢量特征产生重大影响。这个调制过程使得重要性的梯度可以后向传播到没有被选择的点上,从而模型可以根据任务损失,自动调整参数使相对重要的点得以保留,从而达到根据图片内容和任务目标自适应下采样的效果。
最后,文章中还提到了 grid prior。作者提出,如果只根据特征计算 「重要性」,而完全忽视点的 2D 位置,将会在无特征的区域内(如大物体表面)造成采样的过度随机。在这种特征均一的区域,理想状况下,模型能够自动退回传统的均匀密度下采样。因此,在选择 token 时,作者在「重要性」 上额外叠加了一层 grid prior,将优先级倾向于那些在传统栅格采样上的点。具体方法参见论文。
4. 解码器(point-based decoder)
传统图像分割的解码器也基于栅格。本文将 Mask2Former 解码器推广到点云,使用 PointConv 代替 3×3 卷积,并在点云上提供了一种实现 deformable attention 的插值方法,从而实现了端到端的、使用自适应下采样的点云方案学习图像分割的网络。
实验
作者们在图像分类和图像分割任务上展示了 AFF 的实验结果。
他们在经典的 ImageNet-1K 数据集上测试 AFF 的图像分类能力。与基线方法 Swin Transformer 相比,无论模型大小,AFF 都有更佳的表现。尤其,AFF 的 1/5 下采样率的版本,不仅超越了 Swin Transformer 的正确率,并且节省了约 30% 的 FLOPs。

作者们在 ADE20K 数据集上实验 AFF 的语义分割能力。同样地,无论模型大小,AFF 的 1/5 下采样率的版本,不仅超越了基线的表现,并且节省了约 30% 的 FLOPs。

最后,作者们在 Cityscapes 数据集上进行了实例分割和全景分割的实验。实验结果证明,AFF 的自适应能力十分适合 cityscapes 中大小物体差距极大的室外场景。尤为瞩目的是,AFF-Tiny 取得了与 Swin-Base 相当的表现,而仅仅使用了 42.6M 参数的 AFF-Small 模型,取得了与使用 197M 参数的 Swin-Large 相当的表现 —— 节省了约 78% 的参数。

以下两个例子有助于我们直观地感受 AFF 的自适应能力如何帮助它在 Cityscapes 上识别远处的小物体。在例一中,即使在 4 次下采样之后,依然有足够多的采样点留存在远处那些在图像中非常小的汽车上。因此,模型才能够成功捕获这些物体;相比之下,基于栅格的模型则会错失这些距离很远的汽车。

在下例中,AFF 比基线算法 Swin Transformer 识别了更多左侧咖啡店中的人头。比起在中间大块的灰色地面上浪费算力,AFF 更灵活地将更多的采样点分配到了马路边上热闹的露天咖啡店里。

总结
AutoFocusFormer 是第一个使用多层自适应下采样的,能够在高分辨率输入上运行的,适合用来执行如图像分割一类像素级预测任务的模型。灵活的数据结构提供了更多样化的下采样率选择,而且实验证明,由于 AFF 能够正确地采样到合适的点,它的 1/5 下采样率模型能够在节省大量计算的前提下,取得超越基线的成绩。综合实验结果来看,AFF 在小物体识别上取得了很大的进步,同时大大节省了 FLOP count 和参数数量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...