

-
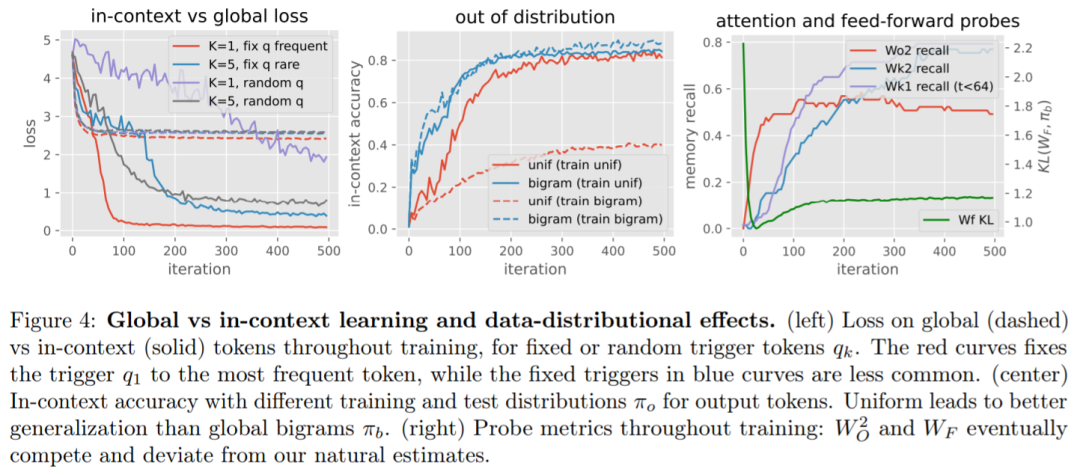
本文引入了一种新的合成设置来研究全局和上下文学习:序列遵循二元语言模型,其中一些二元在序列中变化,而另一些不会。
-
本文将 Transformer 的权重矩阵视为学习存储特定嵌入对的联想记忆,并以此为任务推导出一个简化但更可解释的模型。
-
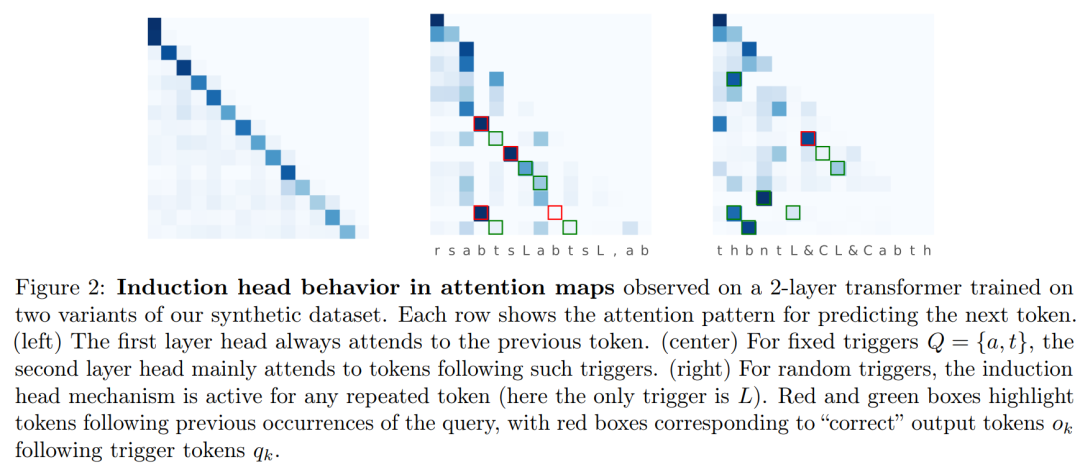
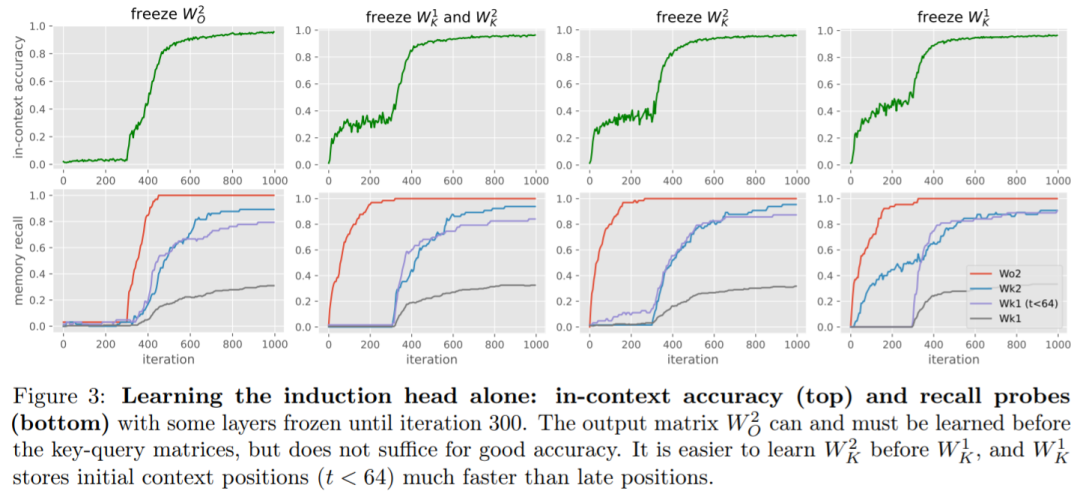
本文对训练动态进行了细致的实证研究:首先学习全局二元,然后以自上而下的方式学习适当的记忆,形成感应头。
-
本文给出了训练动力学的理论见解,展示了如何通过在噪声输入中找到信号,在种群损失上进行一些自上而下的梯度步骤来恢复所需的联想记忆。
方法介绍
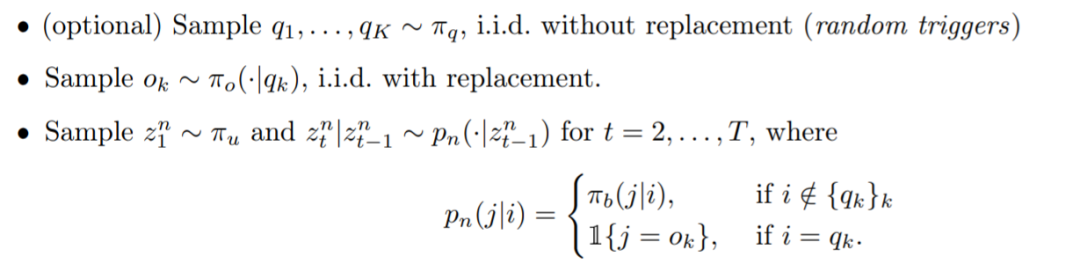
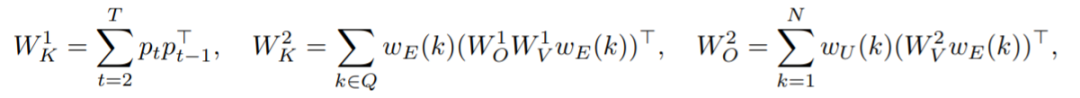
实验
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...