
最近一段时间,随着大语言模型(LLM)的不断发布,LLM 排位赛也变得火热起来,研究者们试图在新的 LLM 评测系统中不断刷新自家模型的分数。

-
论文地址:https://arxiv.org/pdf/2306.08568.pdf
-
代码地址:https://github.com/nlpxucan/WizardLM



WizardCoder 性能如何?
-
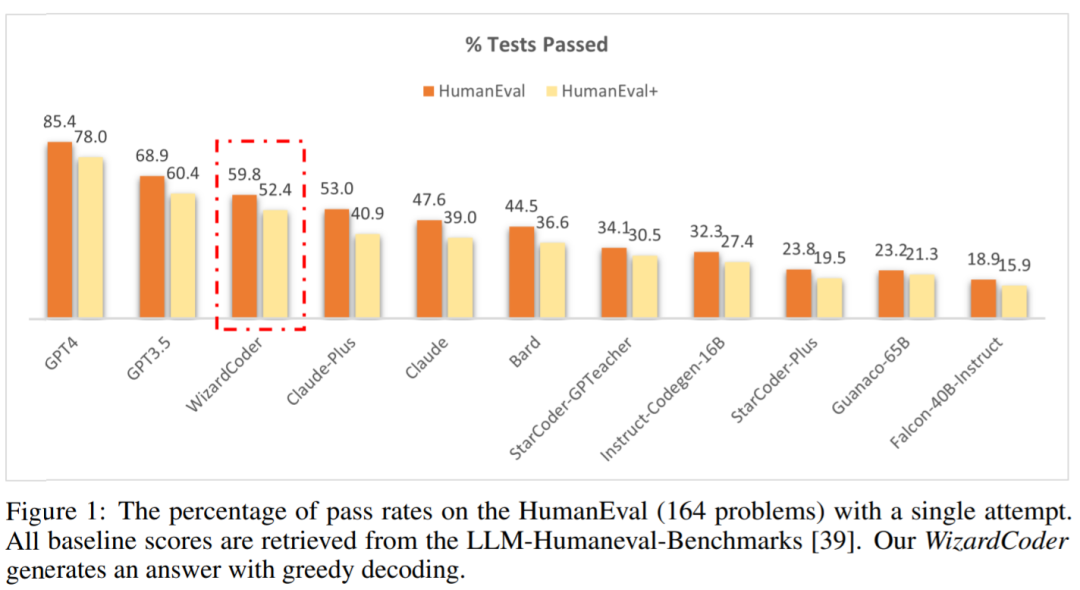
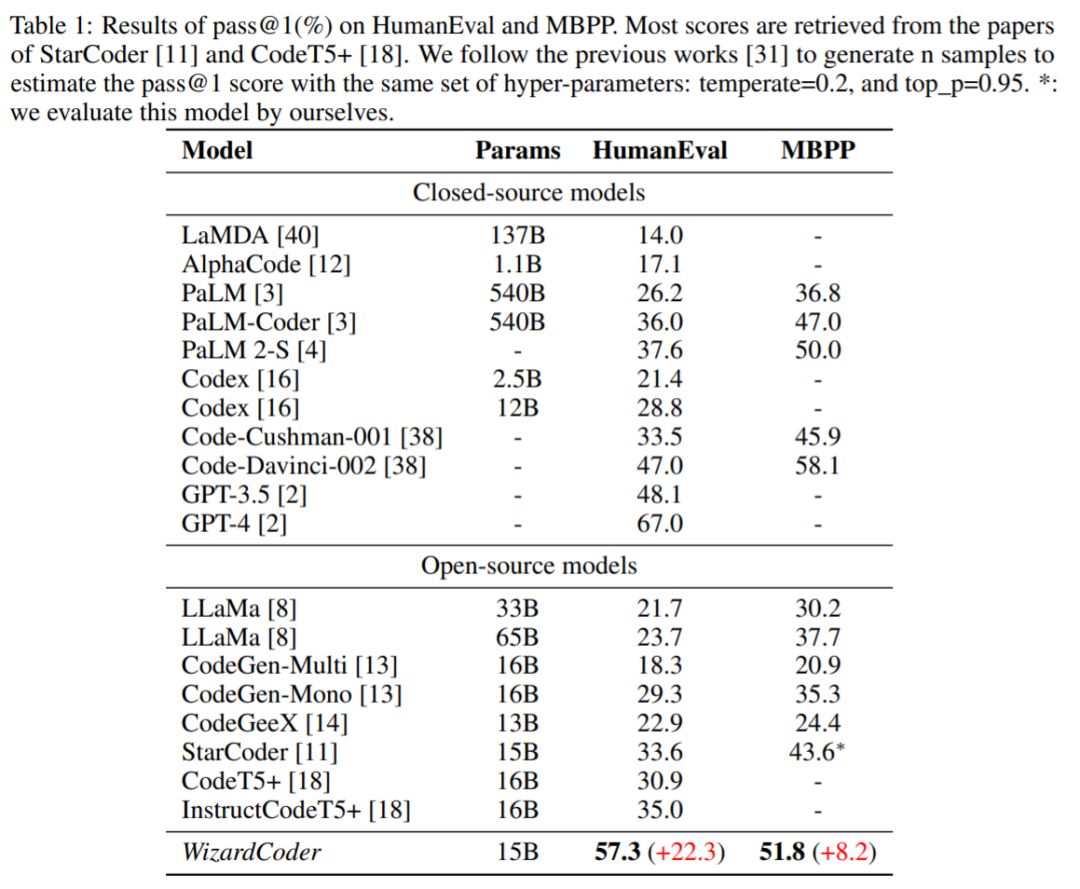
WizardCoder 的性能优于最大的闭源 LLM,包括 Claude、Bard、PaLM、PaLM-2 和 LaMDA,尽管它要小得多。
-
WizardCoder 比所有的开源 Code LLM 都要好,包括 StarCoder、CodeGen、CodeGee 以及 CodeT5+。
-
WizardCoder 显著优于所有具有指令微调的开源 Code LLM,包括 InstructCodeT5+, StarCoder-GPTeacher 和 Instruct-Codegen-16B。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...