
2021 年 12 月 WebGPT 的横空出世标志了基于网页搜索的问答新范式的诞生,在此之后,New Bing 首先将网页搜索功能整合发布,随后 OpenAI 也发布了支持联网的插件 ChatGPT Plugins。大模型在联网功能的加持下,回答问题的实时性和准确性都得到了飞跃式增强。

-
论文地址:https://arxiv.org/abs/2305.06849
-
项目地址:https://github.com/thunlp/WebCPM
WebCPM 研究背景

微软整合 OpenAI ChatGPT 搭建新必应系统
WebCPM 搜索交互界面和数据集
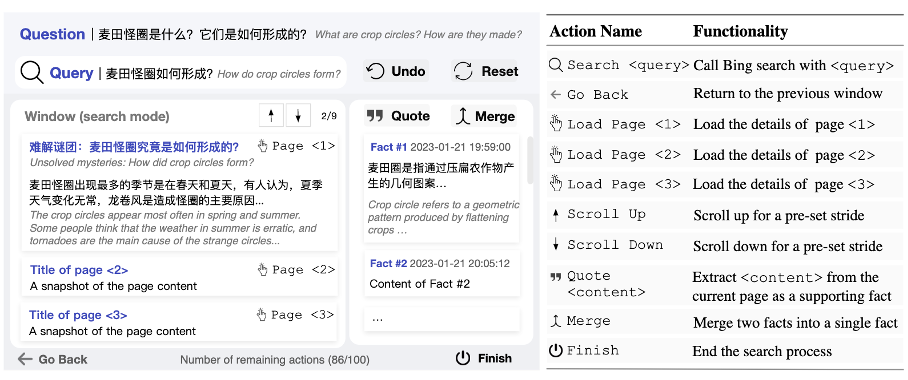
WebCPM 搜索交互界面。
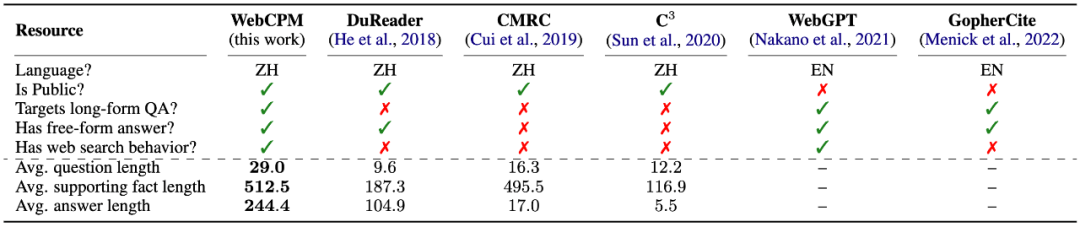
WebCPM 数据集与相关问答数据集的比较。
WebCPM 模型框架

WebCPM 模型框架
搜索模型
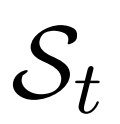
的条件下执行推理。
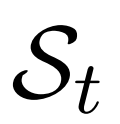
包括原始问题
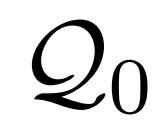
、当前搜索的查询语句
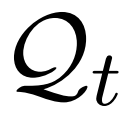
、历史操作序列
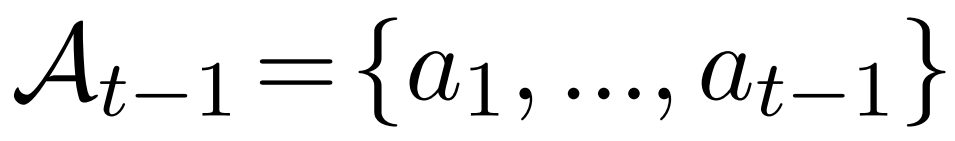
,上一个窗口和当前窗口中显示的内容
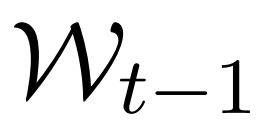
和
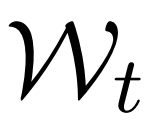
、当前已经摘录的支持事实
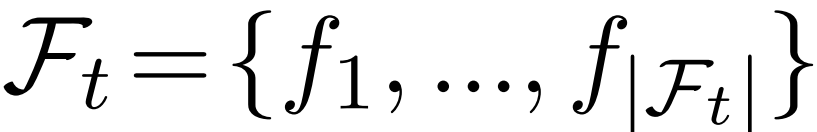
。
答案综合模型
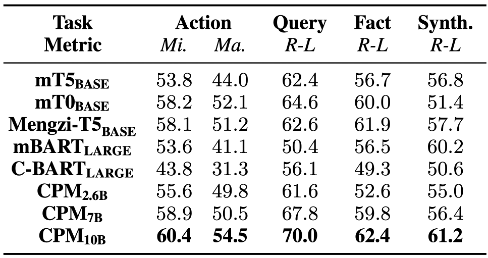
单个子任务的性能评估结果,作者测试了包括 CPM 模型在内的多个有代表性的中文大模型。
单个子任务评估
整体 pipeline 评测
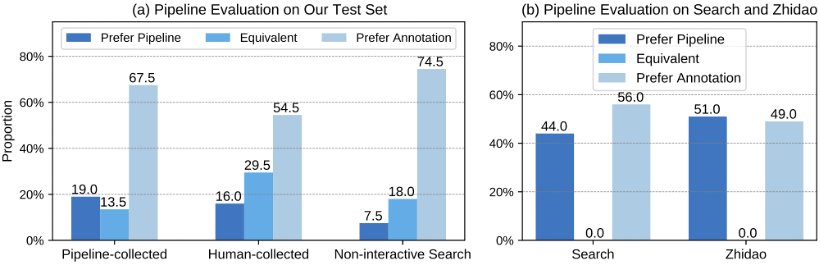
整体 pipeline 评测效果,作者测试了 WebCPM 数据集和 DuReader 数据集
WebCPM 案例分析

WebCPM 成功实践 BMTools

-
BMTools 工具包 :https://github.com/OpenBMB/BMTools
-
工具学习综述链接 :https://arxiv.org/abs/2304.08354
-
工具学习论文列表 :https://github.com/thunlp/ToolLearningPapers
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...