

查询
,ChatGPT 使用
自注意力
机制对 prompt 进行反复编码,其时间和内存复杂度随输入长度呈二次方增长。缓存 prompt 的 transformer 激活可以防止部分重新计算,但随着缓存 prompt 数量的增加,这种策略仍然会产生很大的内存和存储成本。在大规模情况下,即使 prompt 长度稍微减少一点,也可能会带来计算、内存和存储空间的节省,同时还可以让用户将更多内容放入 LM 有限的上下文窗口中。
参数
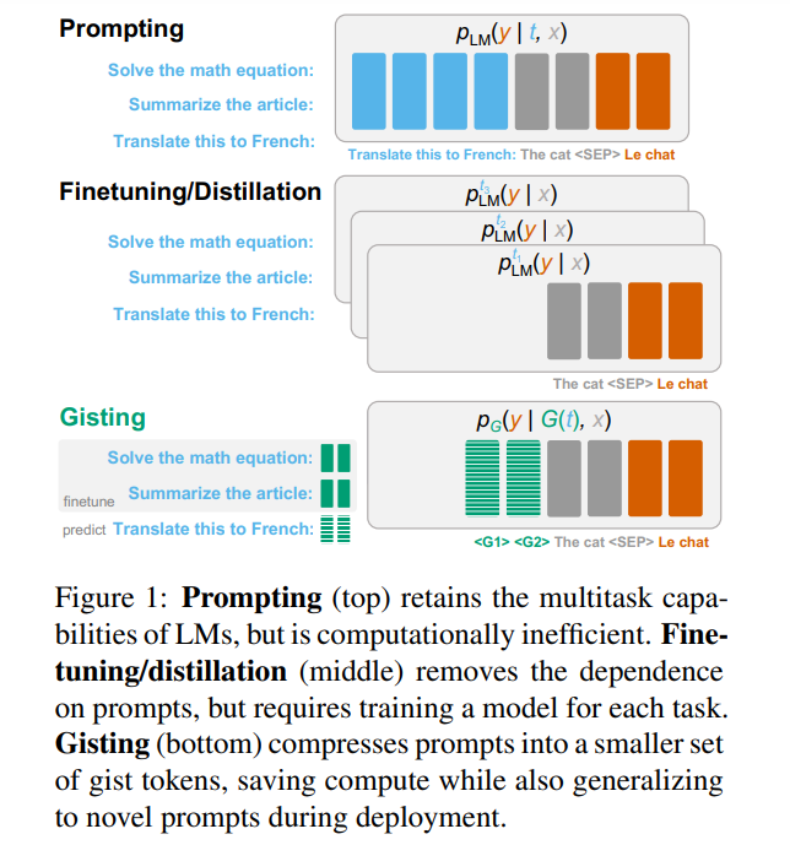
高效的自适应方法。然而,这种方法的一个基本缺点是每次需要为新的 prompt 重新训练模型(下图 1 中间所示)。
梯度下降
为每个任务学习 prefix,而 Gisting 采用
元学习
方法,仅仅通过 prompt 预测 Gist prefix,而不需要为每个任务进行 prefix 学习。这样可以摊销每个任务 prefix 学习的成本,使得在没有额外训练的情况下泛化到未知的指令。

Gisting
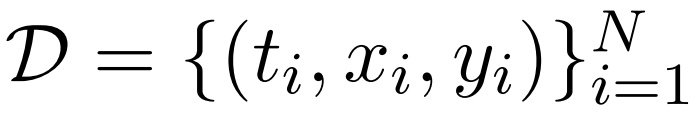
,t 表示用自然语言 prompt 编码的任务 (例如将此翻译成法语),x 表示任务的(可选)输入 (例如 The cat),y 表示期望的输出(例如 Le chat)。指令微调的目的是通过连接 t 和 x,然后让通常预先训练的
语言模型
自回归地预测 y,从而学习分布 pLM(y | t,x)。推理时可以使用新的任务 t 和输入 x 进行 prompt,从模型中解码以获得预测结果。
自注意力
随输入长度呈二次方扩展。因此很长的 prompt,尤其那些被反复重用的 prompt,计算效率低下。有哪些选项可以用来降低 prompt 的成本呢?
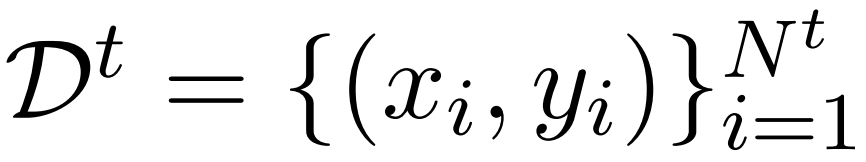
,可以学习一个专门的
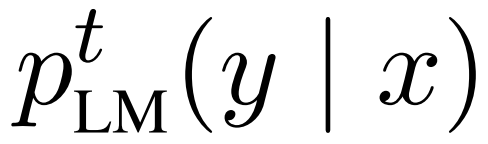
,它更快,因为不需要考虑 t。
参数
高效微调方法能够以比全面微调低得多的成本实现相同的目的。然而仍然存在问题:必须至少存储每个任务的一部分模型
权重
,并且更重要的是,对于每个任务 t,必须收集相应的输入 / 输出对数据集 D^t 并重新训练模型。
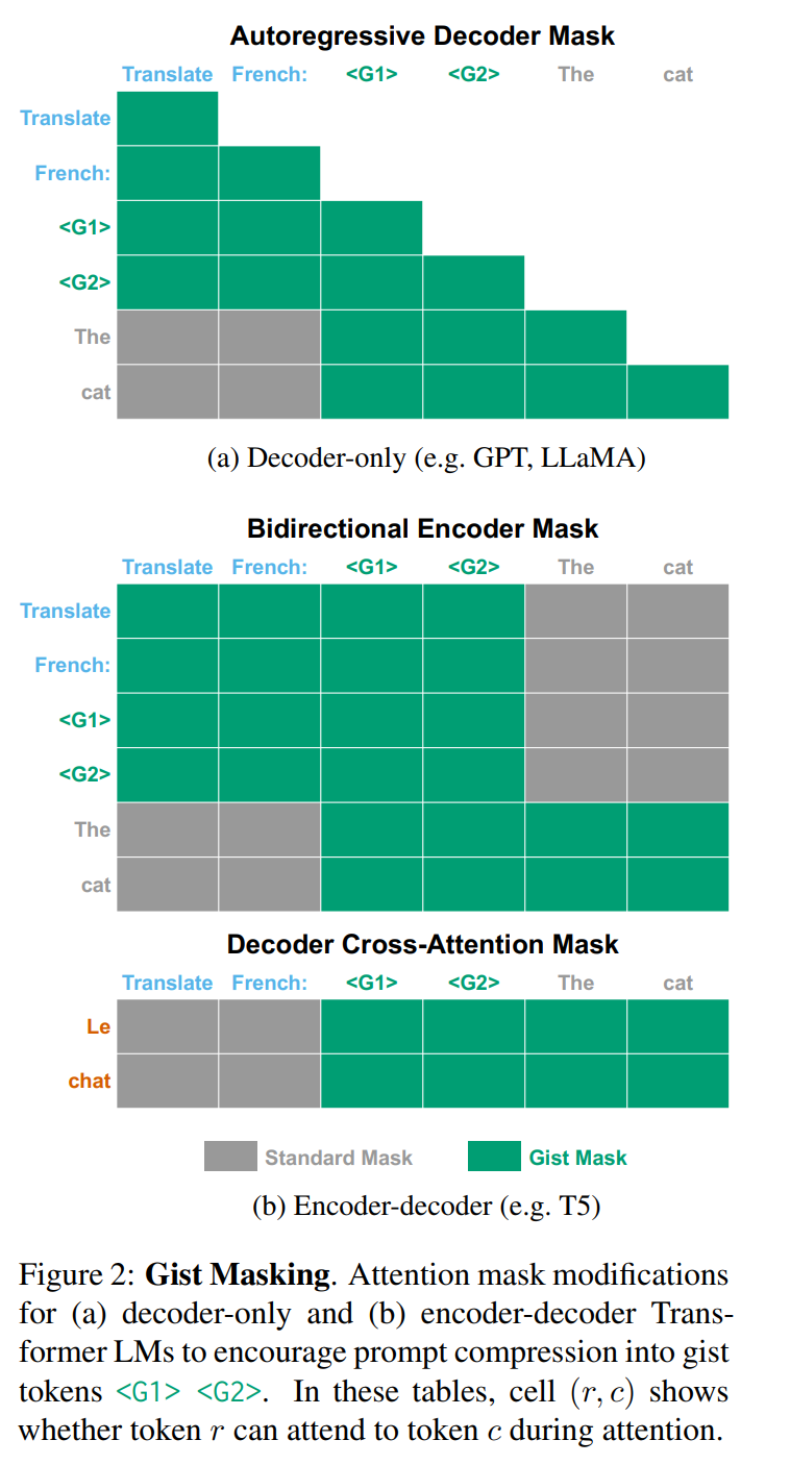
通过掩膜学习 Gisting

。这个序列被输入到模型中,有一个限制,即在 gist token 之后的输入 token 不能参考之前的 prompt token(但它们可以参考 gist token)。这会强制模型将 prompt 中的信息压缩成 gist token,因为输入 x (输出 y) 无法处理 prompt t。
实验结果
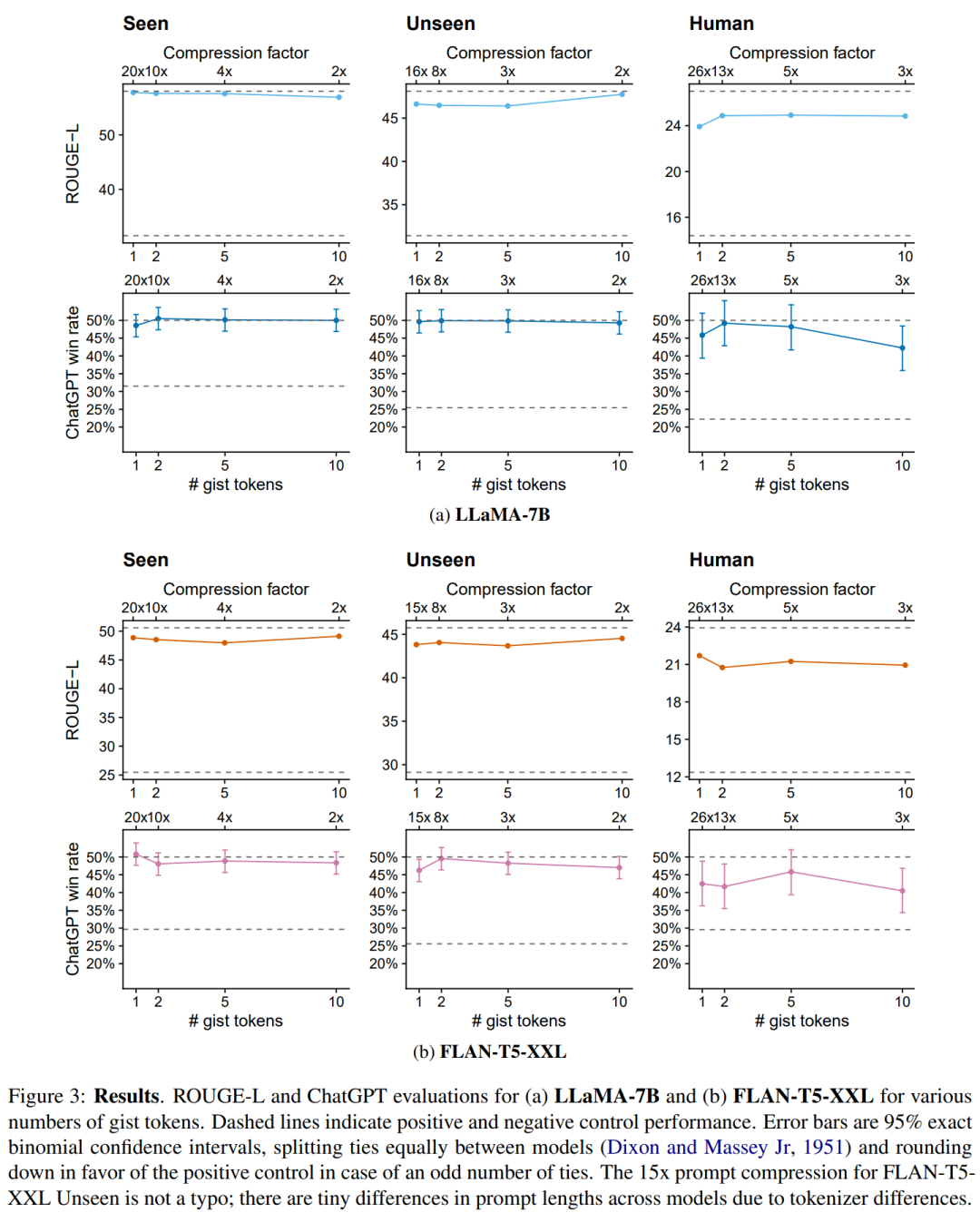
过拟合
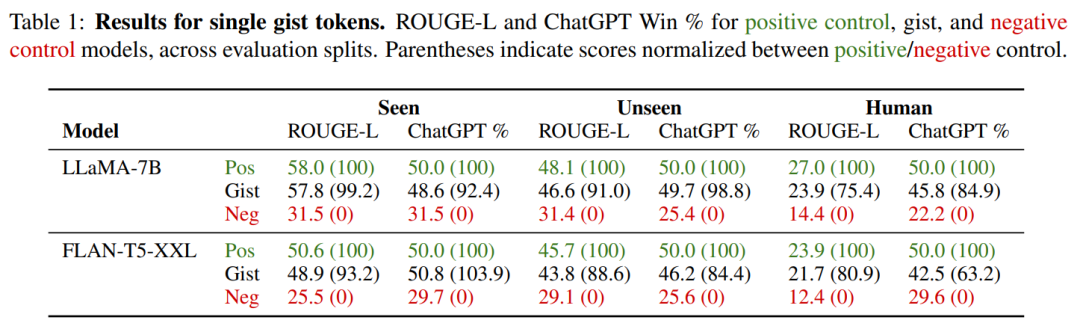
。因此,研究者在下表 1 中给出了单 token 模型的具体数值,并在剩余实验中使用单个 gist 模型。
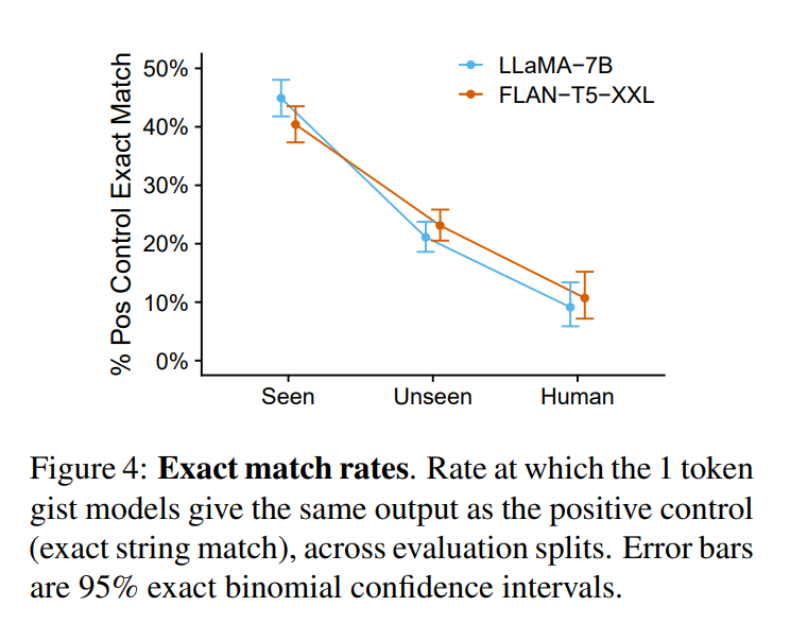
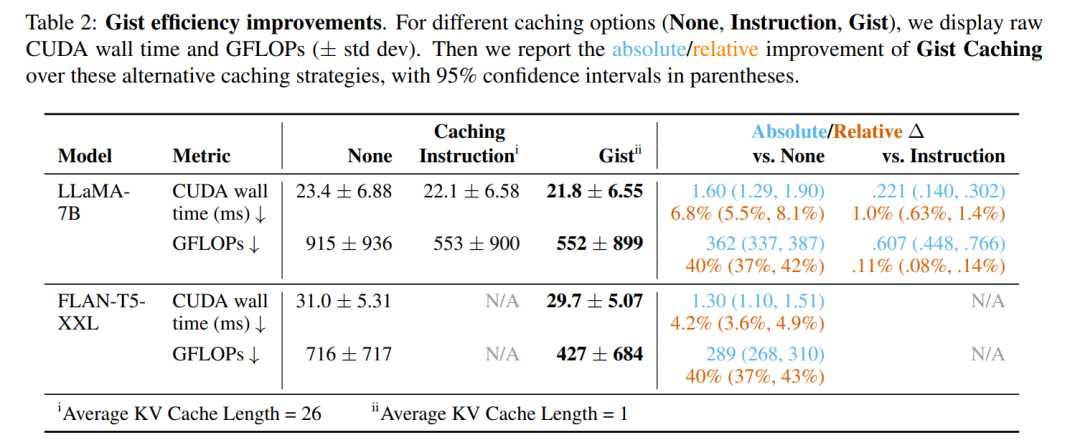
计算、内存和存储效率
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...