
计算成本是人们打造 ChatGPT 等大模型面临的重大挑战之一。
参数
量从 1.17 亿增加到了 1750 亿,预训练数据量从
5G
B 增加到 45TB,其中 GPT-3 训练一次的费用是 460 万美元,总训练成本达 1200 万美元。
参数
的
语言模型
时每秒 1 个 token,但令人印象深刻的是,它已经把不可能变成了可能。
语言模型
(LLM)推理的高计算和内存要求使人们必须使用多个高端 AI 加速器进行训练。本研究探索了如何将 LLM 推理的要求降低到一个消费级 GPU 并实现实用性能。
线性规划
优化器
,它搜索存储和访问
张量
的最佳模式,包括
权重
、激活和注意力键 / 值(KV)缓存。FlexGen 将
权重
和 KV 缓存进一步压缩到 4 位,精度损失低到可以忽略不计。与最先进的 offloading 系统相比,FlexGen 在单个 16GB GPU 上运行 OPT-175B 的速度提高了 100 倍,并首次实现了 1 token/s 的实际生成吞吐量。如果提供了更多的分布式 GPU,FlexGen 还带有流水线并行 runtime,以允许在解码时进行超线性扩展。
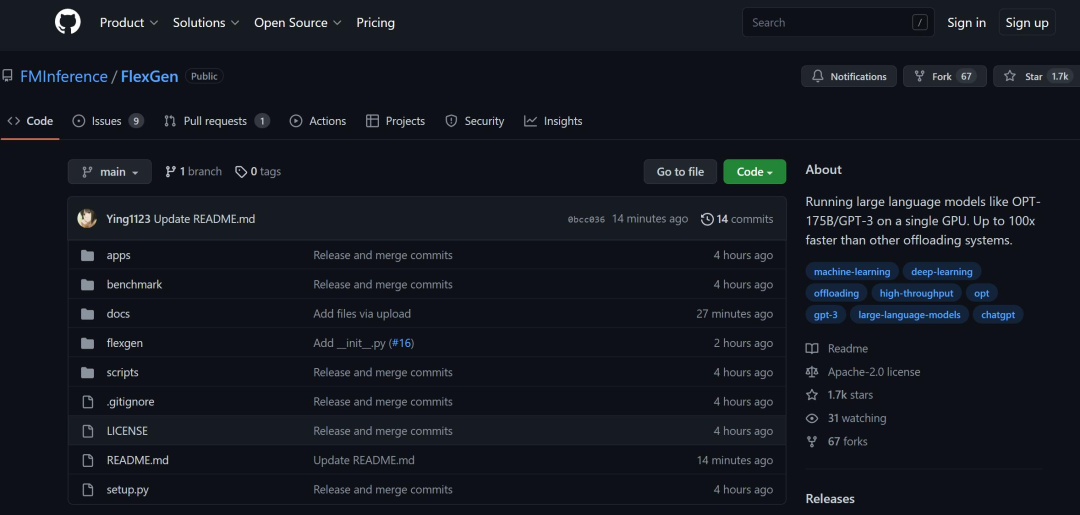
简介
语言模型
在广泛的任务中表现出卓越的性能。LLM 在展现出前所未有的通用智能的同时,也让人们在构建时面临着前所未有的挑战。这些模型可能有数十亿甚至数万亿个
参数
,这导致运行它们需要极高的计算和内存要求。例如,GPT-175B(GPT-3)仅用于存储模型
权重
就需要 32
5G
B 的内存。要让此模型进行推理,至少需要五块英伟达 A100(80GB)和复杂的并行策略。
参数
规模的模型。
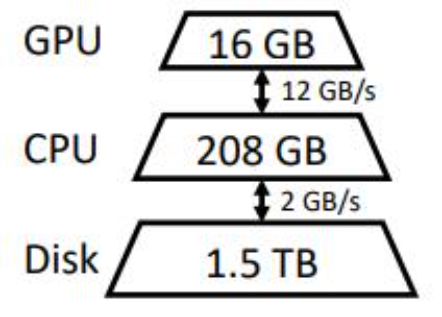
基准
测试、信息提取、数据整理等应用中很受欢迎。实现低延迟对于 offloading 来说本质上是一个挑战,但是对于面向吞吐量的场景,可以大大提高 offloading 的效率。图 1 说明了三个具有 offloading 的推理系统的延迟吞吐量权衡。通过仔细的
调度
,I/O 成本可以通过大量输入分摊并与计算重叠。在研究中,作者展示了就单位算力成本而言,单块消费级 GPU 吞吐量优化的 T4 GPU 效率要比云上延迟优化的 8 块 A100 GPU 的效率高 4 倍。
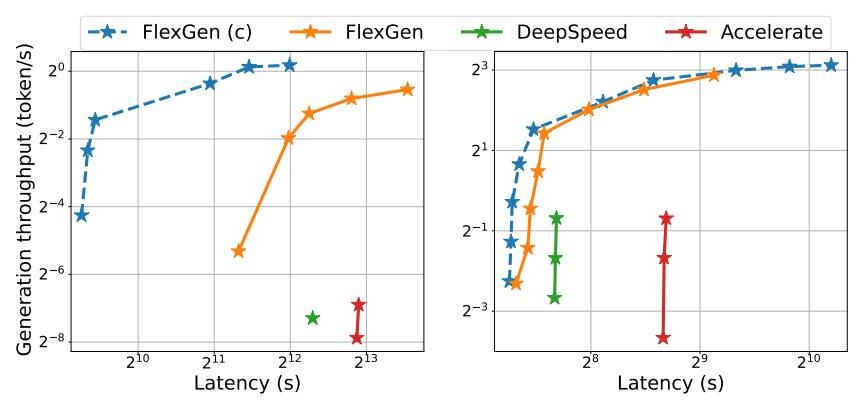
图 1. OPT-175B(左)和 OPT-30B(右)上三个基于 offloading 的系统的延迟和吞吐量权衡。FlexGen 实现了新的帕累托最优边界,OPT-175B 的最大吞吐量提高了 100 倍。由于内存不足,其他系统无法进一步提高吞吐量。
参数
外,它还需要顺序解码并维护一个大的注意力键 / 值缓存(KV 缓存)。现有的 offload 系统都无法应对这些挑战,因此它们执行过多的 I/O,只能实现远低于硬件能力的吞吐量。
张量
:
权重
、激活和 KV 缓存。该策略应指定在三级层次结构上的卸载内容、位置以及卸载时机。其次,逐个 batch、逐个 token 和逐个 layer 计算的结构形成了一个复杂的依赖图,可以通过多种方式进行计算。该策略应该选择一个可以最小化执行时间的时间表。这些选择共同构成了一个复杂的设计空间。
调度
I/O 操作,作者也讨论了可能的压缩方法和分布式管道并行性。

线性规划
求解器搜索最佳策略。值得关注的是,研究人员证明了搜索空间捕获了一个几乎 I/O 最优的计算顺序,其 I/O 复杂度在最优计算顺序的 2 倍以内。搜索算法可以针对各种硬件规格和延迟 / 吞吐量限制进行配置,从而提供一种平滑导航权衡空间的方法。与现有策略相比,FlexGen 解决方案统一了
权重
、激活和 KV 缓存的放置,从而实现了更大的 batch size。
权重
和 KV 缓存压缩到 4 位,而无需重新训练 / 校准,精度损失可忽略不计。这是通过细粒度分组
量化
实现的,可以显著降低 I/O 成本。
运行机制
线性规划
优化器
,它搜索存储和访问
张量
的最佳模式,包括
权重
、激活和注意力键 / 值 (KV) 缓存。FlexGen 将
权重
和 KV 缓存进一步压缩到 4 位,精度损失可以忽略不计。
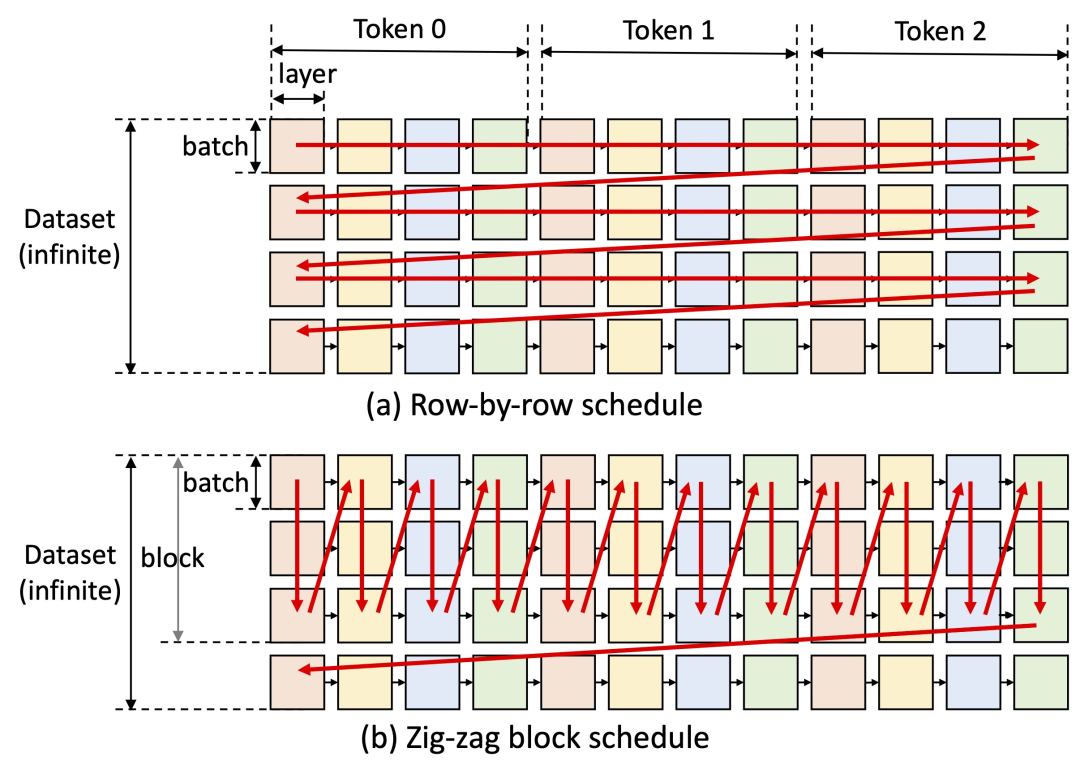
调度
来重用
权重
并将 I/O 与计算重叠,如下图 (b) 所示,而其他基线系统使用低效的逐行
调度
,如下图 (a) 所示。
语言模型
的障碍正在被逐渐克服,希望在今年之内,单机就能搞定 ChatGPT。
语言模型
,结果如下:

逻辑
似乎比较清晰,或许未来的游戏中,我们能看见这样的 NPC?
参考内容:
https://news.ycombinator.com/item?id=34869960
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...