

论文链接:https://arxiv.org/pdf/2302.06476.pdf
大型
语言模型
(LLM)已经被证明能够解决各种
自然语言处理
(NLP)任务,而且对于给定的下游任务,它们不依赖任何训练数据,借助适当的 prompt 就能实现模型调整。这种根据指令执行新任务的能力可以被视为迈向
通用人工智能
的重要一步。
尽管目前的 LLM 在某些情况下取得了不错的性能,但在 zero-shot 学习中仍然容易出现各种错误。此外,prompt 的格式可以产生实质性的影响。例如,在 prompt 中添加「Let’s think step by step」,模型性能就能得到显著提升。这些限制说明当前的 LLM 并不是真正的通用语言系统。
强化学习
(RLHF)」训练 GPT-3.5 系列模型而创建的。RLHF 主要包括三个步骤:使用
监督学习
训练
语言模型
;根据人类偏好收集比较数据并训练奖励模型;使用
强化学习
针对奖励
模型优化
语言模型
。通过 RLHF 训练,人们观察到 ChatGPT 在各个方面都具有令人印象深刻的能力,包括对人类输入生成高质量的响应、拒绝不适当的问题以及根据后续对话自我纠正先前的错误。
命名实体识
别和情感分析。借助广泛的实验,研究者旨在回答以下问题:
-
ChatGPT 是一个通用的 NLP 任务求解器吗?ChatGPT 在哪些类型的任务上表现良好?
-
如果 ChatGPT 在某些任务上落后于其他模型,那原因是什么?
主要结论
-
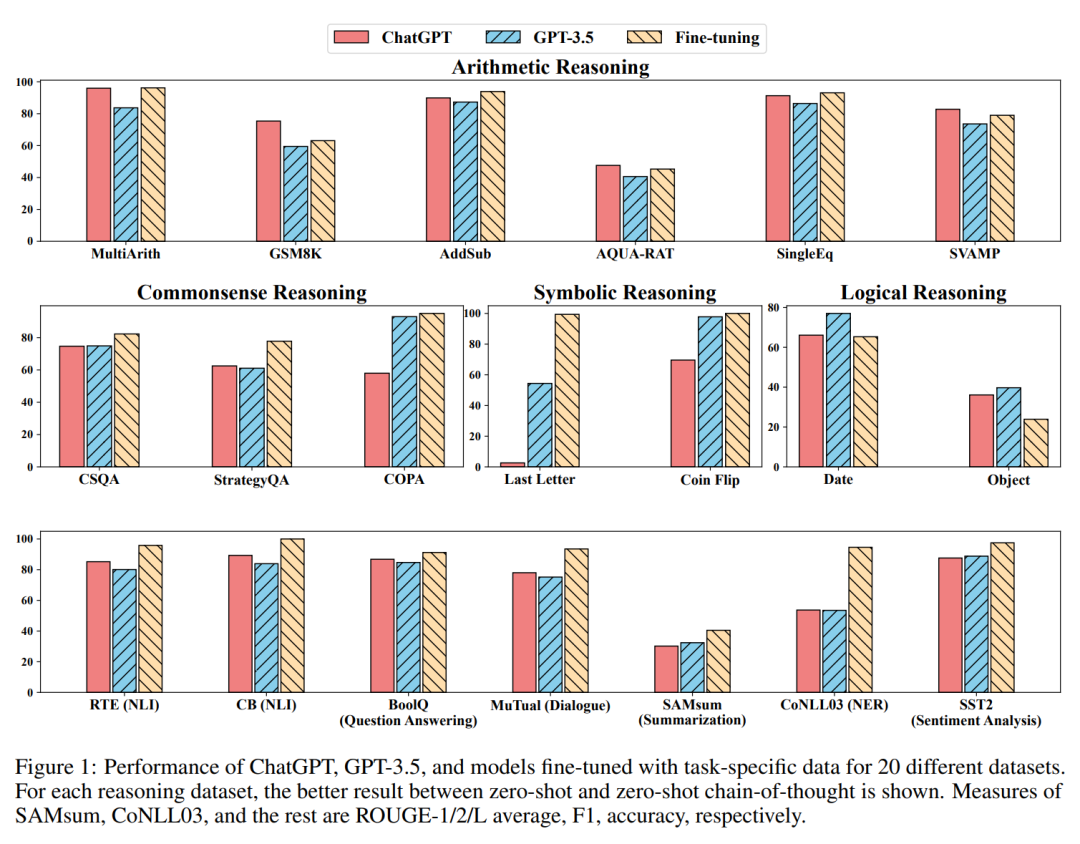
虽然 ChatGPT 作为一个通才模型显示了一些可以执行多个任务的能力,但它通常比针对给定任务进行微调的模型表现要差(见图 1 和第 4.3 节)。
-
ChatGPT 的卓越推理(reasoning)能力在
算术
推理任务中得到了实验证实(第 4.2.1 节)。然而,ChatGPT 在常识、符号和
逻辑
推理任务中的表现通常不如 GPT-3.5,例如通过生成不确定的响应可以看出来(第 4.2.2 节)。
-
ChatGPT 在偏向于推理能力的自然语言推断任务(第 4.2.3 节)和问答(阅读理解)任务(第 4.2.4 节)方面优于 GPT-3.5,例如确定文本对中的
逻辑
关系。具体来说,ChatGPT 更擅长处理与事实一致的文本(即,更擅长对蕴含而不是非蕴含进行分类)。
-
ChatGPT 在对话任务方面优于 GPT-3.5(第 4.2.5 节)。
-
在摘要任务方面,ChatGPT 会生成更长的摘要,比 GPT-3.5 表现要差。然而,在 zero-shot 指令中明确限制摘要长度会损害摘要质量,从而导致性能降低(第 4.2.6 节)。
-
尽管显示出作为通才模型的前景,但 ChatGPT 和 GPT-3.5 在某些任务上都面临挑战,例如序列标注(第 4.2.7 节)。
-
ChatGPT 的情感分析能力接近 GPT-3.5(第 4.2.8 节)。
方法
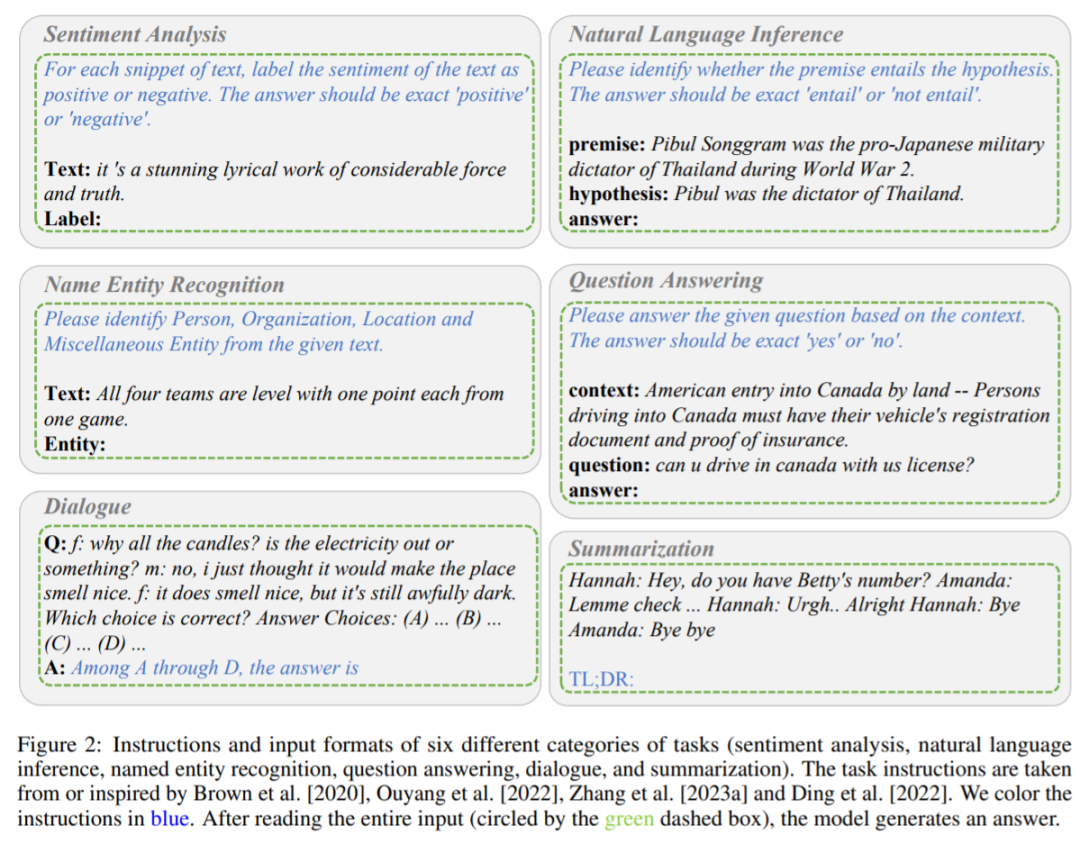
包含六种任务(情感分析、
自然语言推理
、
命名实体识
别、问答、对话和摘要)的指令和输入格式。指令为蓝色字体。

推理任务说明。
查询
时,都要提前清除对话,以避免前面示例的影响。
实验
实验用 20 个不同的数据集来评估 ChatGPT 和 GPT-3.5,涵盖 7 类任务。
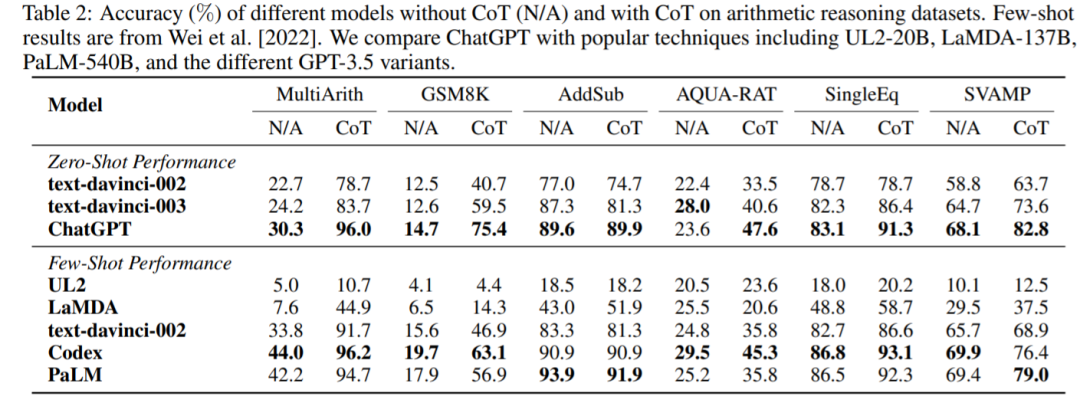
算术
推理
算术
推理数据集上的
准确率
如表 2 所示。在没有 CoT 的实验中,ChatGPT 在其中 5 个数据集上的性能优于 GPT-3.5,显示了其强大的
算术
推理能力。

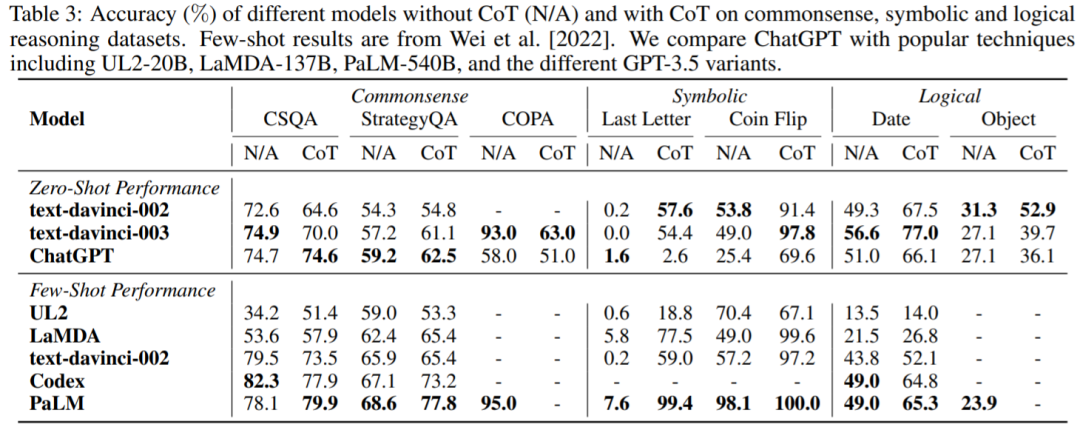
常识、符号和
逻辑
推理
逻辑
推理数据集上的
准确率
。可以得到如下观察结果:首先,使用 CoT 可能并不总是在
常识推理
任务中提供更好的性能,
常识推理
任务可能需要更细粒度的背景知识。其次,与
算术
推理不同,ChatGPT 在很多情况下的表现都比 GPT-3.5 差,说明 GPT-3.5 的相应能力更强。

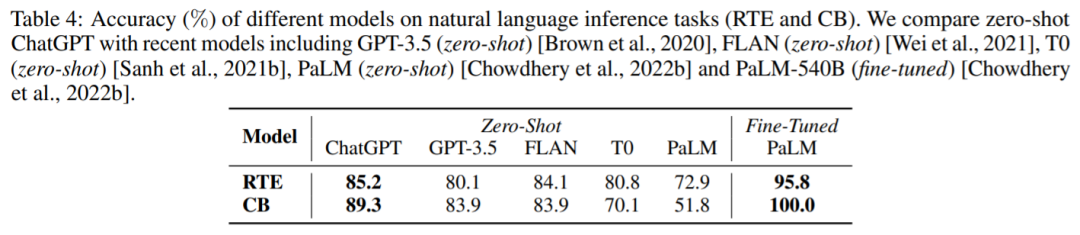
自然语言推理
自然语言推理
任务上的结果:RTE 和 CB。我们可以看到,在 zero-shot 设置下,ChatGPT 可以取得比 GPT-3.5、FLAN、T0 和 PaLM 更好的性能。这证明 ChatGPT 在 NLP 推理任务中,具有较好的 zero-shot 性能。
问答
准确率
,ChatGPT 优于 GPT-3.5 。这表明 ChatGPT 可以更好地处理推理任务。

对话
准确率
。正如预期的那样,ChatGPT 大大优于 GPT-3.5。

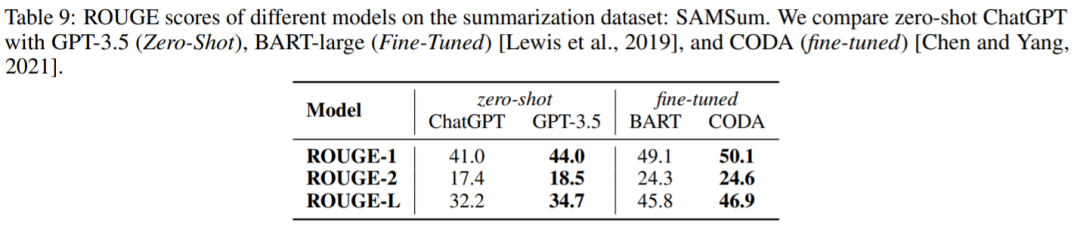
生成摘要
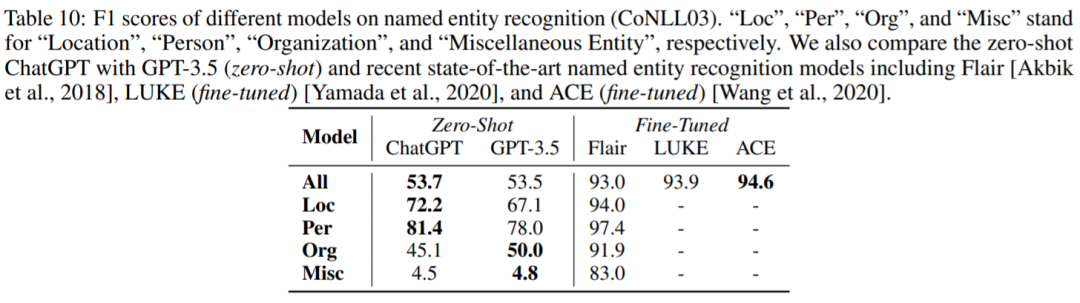
命名实体识
别
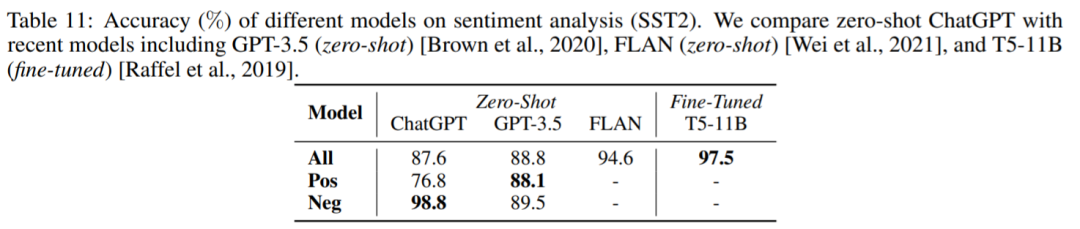
情感分析
准确率
。令人惊讶的是,ChatGPT 的表现比 GPT-3.5 差了大约 1%。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...