墨芯当选“2022中国AI芯片企业50强”。


云端AI芯片市场持续扩容
稀疏化计算有力满足下游市场降本增效的需求

稀疏化计算相较于业内其他AI加速技术,并不是微量的差异化创新,而是能够让性能带来十倍、百倍的创新。
S30计算卡
算力超90000 FPS
TCO约为竞品1/3
®️
,分别为单芯片卡、双芯片卡和三芯片卡,专注于数据中心AI推理应用,可广泛应用于互联网、运营商、生命科学、自动驾驶等众多AI推理场景,满足客户对性能和功耗不同的组合需求。
®️
是首个商用高稀疏率芯片,于2022年元旦一次流片成功,实测性能颠覆性提升。基于Antoum
®️
的单芯片计算卡S4首次推出后经过多方性能实测,具有以下特点:
1
高吞吐:
2
低功耗:
3
低延时:
墨芯板卡S4(单颗Antoum
®️
)对比主流GPU产品,延时可以做到后者的1/4~1/5

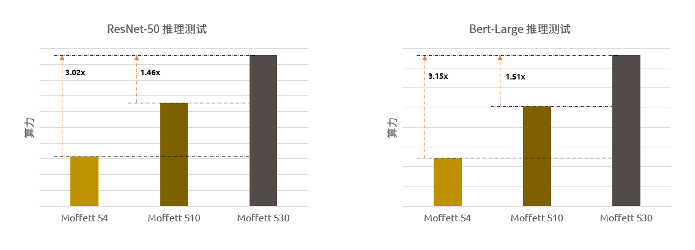
TCO为主流竞品约1/3
已有多家客户
稀疏化生态发力三大市场
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...