
2D&3D融合
以自动驾驶场景为例,自动驾驶汽车需要使用传感器来识别车辆周围的物理环境,用来捕获2D视觉数据,同时在车辆顶部安装雷达,用以捕捉精确目标定位的3D位置数据。

激光雷达生成的点云数据可用于测量物体的形状和轮廓,估算周围物体的位置和速度,但点云数据缺少了RGB图像数据中对物体纹理和颜色等信息的提取,无法精确地将对象分类为汽车、行人、障碍物、信号灯等。
所以需要将包括丰富的语义信息2D视觉图像和可以提供精确的目标定位3D点云数据进行融合,使自动驾驶系统能够精确地了解周围环境,准确做出判断,让自动驾驶功能得以广泛应用。
在O1平台2D&3D融合标注界面,点击2D图片上的小眼睛预览按钮,可以看到3D数据高亮的部分,哪个方位的数据会被映射在2D图片上。
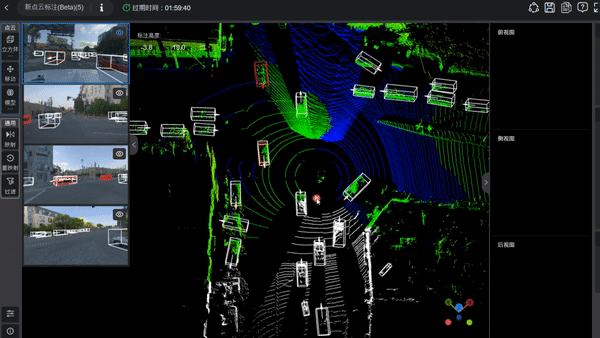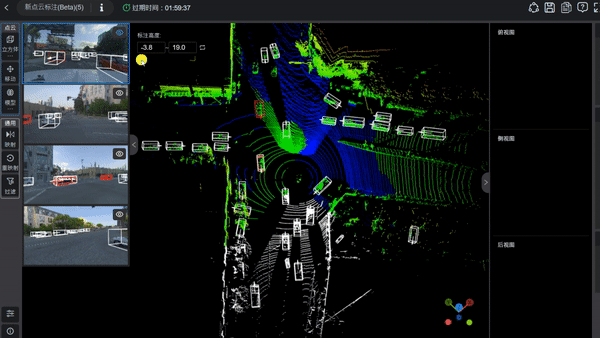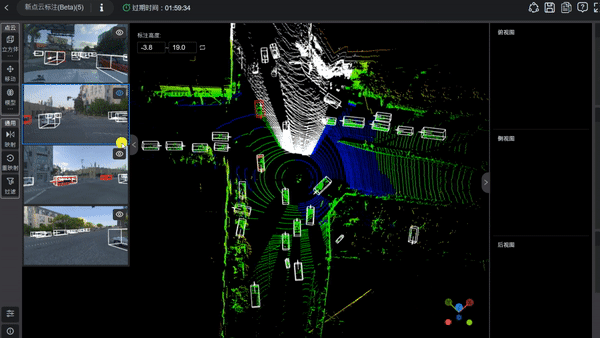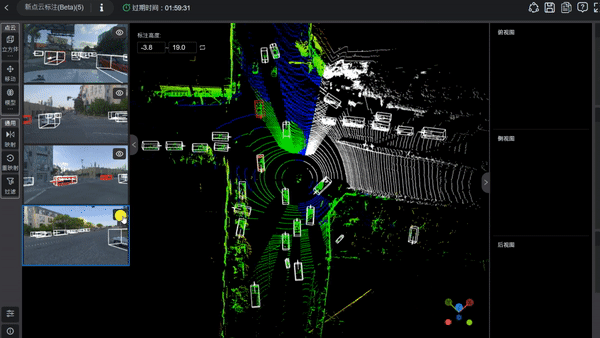
3D框标注
新建3D框
屏幕聚焦在车或目标物体的正上方,点击快捷键F,依次点击左后方,左前方和右前方。平台的自动框收敛的功能可以使3D框完美贴合在目标物体上。

最后选择标签和属性信息,即可完成一个3D框的标注了。
调整3D框
想要调整3D框,可从右侧的三视角图中来调节,分别的从正上方,侧方和后方来观察框中的目标。

一般会通过快捷键来操作:用Z,X来旋转角度,用AWSD从上下左右在侧方视角调节位置,在后方视角用QE来做左右平移。
2D映射
在标注3D数据的同时,可以注意到,左边的RGB数据中,也产生了框。这是通过3D点云数据的标注结果,经过相机参数的计算,投影到RGB数据上。

·支持在RGB数据上显示,调节,新增3D框
·支持在RGB数据上显示,调节,新增2D框
·支持将RGB和3D点云数据上的框相关联
模型预处理
系统预制了多个模型,其中就包括了3D点云预识别模型。只需要点击“模型”,即可一键生成框和标签!

通用模型能对大部分的目标进行正确的识别,但是还会有个别的框需要人工调整。
我们还是通过三视图来手动微调预处理的结果,从而使所有的框可以完美地贴合目标。
比较难标注的目标
有些物体由于被遮挡或者距离自主车辆很远的原因,很难通过有限的点云来确定物体的轮廓和标签。

我们可以通过左下角的
设置
,将点的尺寸调大一些。放大之后,再新建框,并通过左边的2D图来帮助识别物体的标签。
以上便是关于2D&3D融合数据标注的介绍。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...