
随着 NLP 和 CV 的日益融合,
多模态学习
越来越受到学界和业界的重视。在 DALL-E、Stable Diffusion 等
文本生成
图像跨模态应用成熟之后,围绕
多模态学习
、AIGC 等议题的讨论热度持续攀升。
当然,还有很多问题需要进一步探索:比如,
多模态学习
在哪些任务上还有极具前景的应用潜力?多模态技术在真实场景中的泛化受到哪些限制?
11 月 19 日,小红书 REDtech 青年技术沙龙 – 北京站圆满收官。在这场活动上,数位顶尖学者、小红书技术团队大神和青年学子们齐聚一堂,对多模态技术、AIGC、青年人才职业发展等热门议题进行了深入讨论。
人工智能
研究院研究员曹越,此外,本场沙龙还为即将投身业界的高校学子特别设置了嘉宾对谈、自由交流等环节。北京师范大学
人工智能
学院黄华教授与小红书技术副总裁风笛。为青年人才们提供了很多有益的学术研究指导与建议。

多模态衍进之路
多模态学习
的本质,可以理解为从包括文本、图像、视频、音频等不同模态的信息中学习并且提升自身算法。此前,对于不同模态的数据,大家使用的是不同的网络架构,比如 CV 领域使用 Convolution,NLP 领域使用 Transformer,图领域使用
图网
络。
多模态学习
的发展是如何打破「分界线」,促使
人工智能
走向统一的?作为本场沙龙的学界代表之一,北京智源
人工智能
研究院研究员曹越从理论研究的角度切入,回溯了多模态的衍进之路。

自监督学习
、
多模态学习
。在
清华大学
取得博士学位之后,曹越加入了
微软亚洲研究院
视觉计算组。期间参与了多项重要研究,包括 Swin Transformer、GCNet、SimMIM 与 VL-BERT 等。2021 年,Swin Transformer 获得了 ICCV 最佳论文奖—马尔奖。
人工智能
领域在逐渐走向统一。
机器学习
时代,这种统一表现在范式上。很久之前,对于不同任务,研究者需要实现手动设计规则来完成任务。后来,模型可以从历史数据中进行学习,并且进行预测。在这个过程中,研究者需要做的是针对不同的任务设计相应的模型、损失和算法。到了
深度学习
时代,这种统一更多体现在架构上。不同任务都开始使用
深度神经网络
,包括 CNN、RNN、LSTM 等。
卷积神经网络
,对于文本则使用 Transformer,二者的
表征学习
过程是不同的。这种规则也在发生变化。
卷积神经网络
在很长一段时间都占据主导地位。2017 年后,Transformer 大放异彩,一些研究人员致力于将其应用到
计算机视觉
中。学术界发现 Transformer 的网络结构设计可以几乎不经过任何改变直接应用到视觉信号。于是不管是
自然语言处理
还是视觉类任务,都开始使用 Transformer 作为基础架构单元。这方面也有很多代表作,比如 ViT、DeiT、Swin Transformer 等。
语言学
习过程中的自监督预训练不需要额外进行标注。借助这种方式,视觉模型也可以利用几乎无限的数据进行预训练模型之后,并在一系列下游任务中取得非常瞩目的性能提升。这方面的代表作有BEiT、SimMIM、MAE等。
小红书的多模态实践
表征学习
…… 这样的生态带来了很多前沿的技术挑战,小红书已经成为了多模态相关技术的绝佳落地场和领先实践场,为小红书的技术人提供了广阔的成长空间。

智能模板、一键成片、一键添加闪光点等功能。
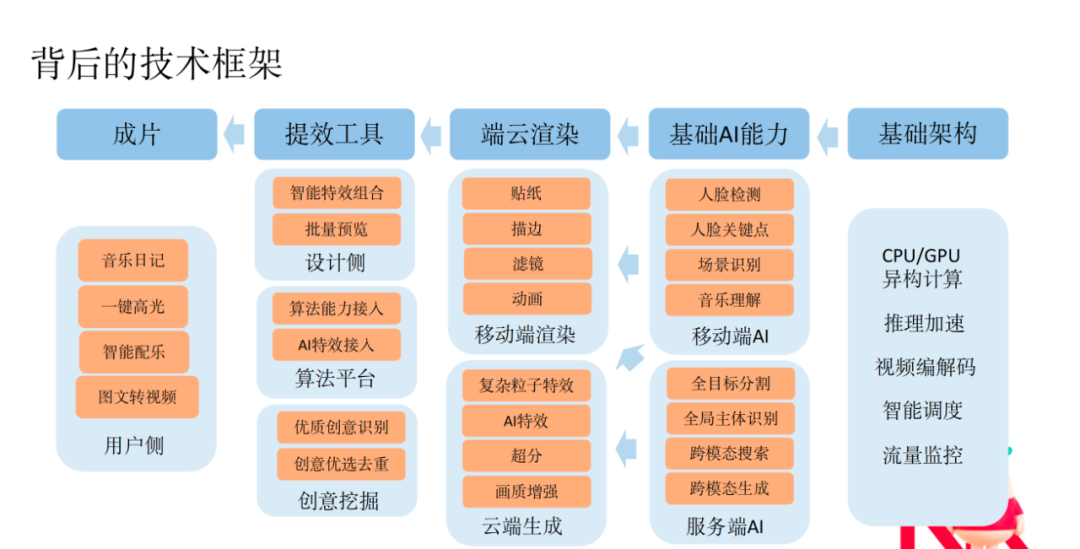
鉴于小红书站内有非常多优质图文数据、笔记评论以及外部开源语料,团队基于大规模中文
语料库
和高质量的图文数据,做了小红书版本的多元场景跨模态预训练模型。在基础的训练模型版本上,团队结合具体场景去进行进一步的优化。张德兵介绍说,除了文案推荐之外,视觉元素和音乐之间的关联、歌词之间的关联、内容和模板之间的关联都是各种各样多模态形式,其关联性都可以通过跨模态匹配来建模。而且用户使用过程中会留下越来越多的行为信号,这些信号也可以用来持续优化算法,提升用户体验。

当自动驾驶遇见「多模态」
感知
能力更广泛,比如利用传感器获得的雷达、红外线等感应数据也属于模态信息。
感知
》相关内容。

感知
是非常重要的技术路线。张兆翔表示,自动驾驶场景的
感知
本质上是多模态、多任务的。比如视觉
感知
存在不同场景,这些场景中的尺寸、视角可能又各不相同。一直以来,张兆翔致力于探索模型的自适应性,包括如何解决标注问题、如何适配场景等问题。
图像分割
领域的研究心得。相比于小红书技术实践中常见的人形分割,现实场景中的分割任务更加多样,比如帽子、水杯、路灯等物体。为了降低大量数据标注所带来的成本问题,他和团队将点级标注用于弱监督的全景分割。与完全监督方法所使用的密集的像素级标签不同,点级标注只为每个目标提供一个单点作为监督,大大减少了标注负担。

这项研究《Pointly-Supervised Panoptic Segmentation》亿发表在 ECCV 2022 上。
感知
的对象不仅包括图像,还包括点云,其场景不仅在车上,还包括各种各样智能设备,甚至是扫地机器人。面对大量非结构化的原始数据,张兆翔也尝试引入 Transformer 架构,实现方法上的创新。在一篇 CVPR 2022 论文中,他提出了空间稀疏的单步长 Transformer 结构,完成了主干网络的空间稀疏化,提升了物体检测性能。
「大咖面对面」:给青年人的研究建议
人工智能
学院黄华教授、小红书技术副总裁风笛两位前辈分别从学界和业界角度出发,开展了一场关于「AI 技术提升与实力升级」的对谈。

多模态学习
、AIGC 都属于当下比较火的方向,也引发了大量技术人才的关注。那么,作为一名青年研究者,如何看待瞬息万变的研究热点呢?
人工智能
的理论研究很重要,但是对企业来说,更重要的是落地,所以两种人才都是被需要的。对于 AI 相关专业的学生来说,如果说想去到工业界,就可以尽量多做点技术类的项目,如果想在学术界深造,就多做一些理论方面的工作。
信息检索
、信息推荐、信息理解,特别在智能创作相关技术,以及底层
多模态学习
、统一
表征学习
等方向上,都能提供非常重要的研究源头:数据。
人工智能
方向研究的实验室来说,挑战基本不在于硬件设备的条件,缺少的是真正能够为数亿用户所使用的应用场景,以及这些场景产生的真实数据。很多工作难以与真实用户做交互,更多是基于可能存在偏差的历史数据进行研究。而数据集和真实场景,都是小红书本身具备的优势。此外,小红书还能提供比较强大的算力资源。


© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...